General-Purpose Graphics Processor Architecture
Reference : https://www.morganclaypool.com/doi/10.2200/S00848ED1V01Y201804CAC044
Youtube : https://www.youtube.com/watch?v=4Pi424VJgcE&list=PLxNPSjHT5qvscDTMaIAY9boOOXAJAS7y4&index=1
1. Introduction
1.1 The Landscape of Computation Accelerators
GPU가 이전에 CPU가 하던 일을 많이 대체하고 있습니다. dennard scaling 법칙에 따라 소모 전력에 비해 성능이 좋아진다고 생각하였지만, 이러한 생각은 한계에 부딪혔습니다. 트랜지스터를 더 작게 한다던지 진동수를 더 늘리는 것이 불가능해지면서 하드웨의 진화에는 한계에 부딪혔습니다. 따라서 병렬적으로 코어를 사용하여 발전하고자 합니다. 또는 특정 작업에 특화시켜 이에 대한 효율을 극대화 시키고 있습니다. 하지만 이는 유연성이 부족하기에 좀 더 보편적인 GPU가 등장하게 됩니다. 이는 병렬 프로그래밍을 하는데 특화되어 있습니다.
1.2 GPU Hardware basics
GPU는 독립적으로 계산이 불가능하며 CPU와 연계 되어야만 합니다. CPU는 GPU에 데이터를 보내주고 작업을 시작하는 ㅇ미무를 지니게 됩니다. 이 둘의 차이점은 I/O 장치로의 접근 가능 여부입니다. 그렇다면 CPU와 GPU가 어떻게 연결되어 있는지 알아보겠습니다.

(a)의 경우는 GPU와 CPU가 각자의 메모리를 가지고 이 둘은 bus로 연결되어 이를 통해 통신합니다. NVIDIA가 이러한 설계를 지닙니다. CPU DRAM(system memory)의 경우는 낮은 지연 시간을 위해 최적화된 반면, GPU DRAM(device memory)는 높은 성능을 위해 최적화되어 있습니다. (b)의 경우는 통합 설계 되어 있는데 같은 메모리를 사용하기에 전력 소모에 최적화되어 있습니다. AMD나 모바일의 경우는 이러한 설계를 가집니다.
GPU 계산은 CPU에서 시작하는데, 과거의 GPU의 경우에는 CPU에서 GPU에 사용될 메모리를 관리하게 됩니다. 하지만 최근의 GPU 같은 경우에는 CPU 메모리에서 GPU 메모리로의 데이터 전송을 자동적으로 하드웨어에서 도와 주빈다. 이는 unified memory라고 부르는 가상 메모리 지원에서 이루어집니다. 하지만 캐쉬 일관성(cache-coherence) 문제(공유 메모리 시스템에서 로컬 캐쉬 간의 불일치로 인한 문제)가 발생할 수 있습니다. 다음에는 GPU 계산을 CPU에서 실행시키는데, 이는 CPU의 드라이버에서 수행하게 됩니다. 커널을 통해 코드가 수행되게 되며, 드라이버는 스레드의 수나 사용할 데이터를 특정하여 작업을 수행합니다.
현대의 GPU는 다수의 코어를 지니며 streaming multiprocessor 혹은 compute unit이라 불립니다. 각각의 GPU는 해당 GPU를 실행시킨 커널에서 SIMT(single instruction multiple thread)를 수행하는데, 하나의 GPU에는 수천 개의 스레드가 존재하며, 이는 scratchpad memory(레지스터 기억기로서 코드 일관성 문제를 피하기 위하여 캐시와 같이 빠르면서도 확장성을 가지는 메모리의 필요에 의해 생겼지만 주 메모리 데이터 복사본이 존재하지 않아 컴파일러와 같은 소프트웨어 지원이 필수적이지만 직접 제어 가능합니다)를 통해 통신하며 fast barrier operation에 의해 동기화 됩니다. 수많은 스레드가 존재하기 때문에 메모리 접근에 대한 latency를 감추는 것이 가능합니다.

GPU는 CPU에 비해 산술 로직 유닛을 제어 로직보다 많이 할당함으로서 성능을 올렸습니다.
2. Programming Model
이번 장에서는 그래픽 계산이 아닌 GPU의 활용에 대해서 다루고 있으며, GPU의 설계를 이해하고자 합니다. 현대의 많은 GPU들은 직접 SIMD 하드웨어를 사용하기 보다는 CUDA, OpenCL과 같은 GPU API를 사용하여 다수의 스칼라 스레드를 동작시키며 메모리 접근과 실행을 돕습니다. 이러한 스칼라 스레드들의 집합을 warp라고 하며, 이러한 하나의 명령 단위를 SIMT라고 합니다.
2.1 Execution Model
GPU는 CPU에서 실행을 시작하며, 분리되어 있는 경우는 메모리 할당 및 데이터 전송이 이루어진 후에 계산 커널을 통해 수행되며, 통합된 경우는 커널만 수행하면 됩니다. 계산 커널은 수천개의 스레드들로 이루어집니다. CPU와 GPU의 최적화는 코드상 상이할 수 있습니다.
요즘은 많은 모바일 기계에서 쓰던 CPU와 GPU를 통합한 설계를 컴퓨터로 가져오고 있습니다. 하지만 전통적으로 GPU는 자체 DRAM 메모리를 가지고 있으며, 이는 머신 러닝에 쓰이는 GPU와 같은 경우에는 유지되고 있습니다. NDIVIA에서는 GPU 메모리와 CPU 메모리를 업데이트 시켜주는 Unified Memory를 사용하고 있는데, 이는 프로그래머를 대신하여 복사를 수행합니다.
2.2 GPU Instruction Set Architectures
이번 장에서는 우리는 고수준 언어인 CUDA와 OpenCL을 어셈블리 수준으로 변환시켜 GPU에서 작동시키는 방법에 대해서 알아볼 것입니다. 밑에 내용이 너무 어렵고 저한테는 중요하지 않은 부분인 것 같아 훑고 지나갔습니다. NVIDIA와 AMD가 CUDA와 OpenCL로 어떻게 기존의 HLSL과 OGSL에서 진화하였는 지에 대한 이야기입니다.
3. The SIMT Core: Instruction and Register Data Flow
이번 장에서는 GPU의 구조와 미세구조를 알아봅니다. 이는 크게 두 파트로 이번 장에서는 SIMT 코어를 다음 장에서는 메모리 시스템을 알아볼 것입니다.
전통적인 그래픽 파이프라인에서는 GPU에 요구되는 메모리 대역폭이 너무나도 크기에 off-chip 메모리 대역폭을 구별하여 사용하였지만, 현재는 다수의 스레드에서 조금씩 나눠서 효과적으로 잘라서 사용하고 있습니다.

위의 그림은 GPGPU를 SIMT 앞부분과 SIMD 뒷 부분으로 나누어 표현한 그림입니다. 파이프 라인은 크게 3개의 스케쥴링 루프로 구성되어 있는데, instruction fetch loop, instruction issue loop, register access scheduling loop가 존재합니다. instruction fetch loops는 Fetch, I-Cache, Decode, I-Buffer를, instruction issue loop는 I-Buffer, Scoreboard, Issue, SMIT Stack을, register access scheduling loop는 Operand Collector, ALU, Memory로 구성되어 있습니다. 이번 장에서는 이들의 대략적인 루프를 점진적으로 자세히 뜯어볼 생각입니다.
3.1 One-Loop Approximation
먼저 GPU가 한개의 스케쥴러라고 생각해봅시다. 우리는 코드가 아닌 숨겨진 부분에 대해서 집중해서 볼 것입니다.
효율성을 올리기 위해서 스레드들의 집합을 warps(NVIDIA) 또는 wavefronts(AMD)로 부를 것입니다. 각 사이클에서, 하드웨어는 스케쥴링을 위해 warp 프로그램 카운터에서 warp에서 실행 시킬 다음 명령의 주소를 찾아 접근합니다. 명령을 가져와서 이를 디코딩하고 source operand register를 register file에서 받습니다. 이와 동시에 SIMT 실행 mask 값이 결정됩니다. 스레드들은 if 문이나 여러 조건문을 통해 다른 작업을 하게 될 수 있는데, 이를 사전 예측으로 SIMT execution mask value를 결정하여 진행한다는 것입니다.
참고자료 : https://stackoverflow.com/questions/32086032/divergence-in-gpgpu
3.1.1 SIMT Execution Masking
GPU에서 중요한 것 중 하나인 SIMT exeuction model은 각각의 스레드들이 완전히 독립적으로 실행되도록 합니다. 이는 예측을 통해 가능하지만, 현재의 GPU들은 SIMT stack이라 하는 예측 마스크의 stack과 고전적 예측(flag를 사용)의 조합을 통해 이루어집니다.
SIMT stack의 경우 두 가지 점에서 중요한데, 하나는 중첩된 제어 흐름(nested control flow)로 다른 것에 의존적인 상황을 의미하며(이전에는 다중 예측 레지스터를 사용), 다른 하나는 warp 내 다른 모든 스레드들이 제어 흐름 경로를 피할 때 그에 대한 계산을 전부 스킵할 수 있다는 점입니다. 이는 GPU에서 사용하는 SIMT stack에서도 전부 사용 가능합니다.
SIMT stack을 설명하기 위해 아래의 cuda C 코드와 이를 warp당 4개의 스레드를 가진 GPU에서 어떻게 SIMT stack이 처리하는 지를 알아보겠습니다. CUDA C코드는 아래와 같이 여러 분기점을 가지고 있지만 결국 모두 G 코드에서 동시에 실행되어야만 합니다.
do {
t1 = tid*N; // A
t2 = t1 + i;
t3 = data1[t2];
t4 = 0;
if( t3 != t4 ) {
t5 = data2[t2]; // B
if( t5 != t4 ) {
x += 1; // C
} else {
y += 2; // D
}
} else {
z += 3; // F
}
i++; // G
} while( i < N );하지만 이는 중첩된 if문에 의해 분기점이 생깁니다. 예를 들어 A에서 생긴 분기점에서 몇몇 개의 스레드들은 특정한 작업을 수행하지만, 그렇지 않은 스레드들은 작업을 수행하지 않게 됩니다. 이와 같이 분기점에 따라 스레드들이 다른 행동을 하게 되는데, 현재의 GPU에서는 스레드들의 작업을 (b)와 같이 직렬화(serialize)하여 사용합니다. 이를 스택과 Active Mask를 활용하여 이에 해당하는 스레드들은 작업을 수행하게 합니다. (c) - (e)는 실제로 작업 스택에 대한 것으로, A를 수행하고나서 B와 F로의 분기점에 도달하게 되는데, 이때 보통 스택의 최대 크기를 줄이기 위해서 많은 스레드를 가진 쪽의 작업을 수행합니다. 하지만 이는 유동적입니다. 다음과 같이 B를 먼저 수행하고나면 다시 분기점을 마주치게 되고 스택은 (d)와 같이 됩니다. 이도 똑같이 스택에 작업이 쌓였다가 다시 E에서 다시 모이게 되고, 다시 G에서 모이게 됩니다. 따라서 lock-step하게 작업을 수행할 수 있게 됩니다.

3.1.2 SIMT Deadlock and Stackless SIMT Architectures
NVIDIA에서 2017년에 Volta GPU를 선보였는데, 이는 분기점에서의 masking의 행동과 동기화에서 어떻게 상호작용하는지에 대해서 주목되었습니다. stack 기반의 SIMT는 SIMT 데드락 현상을 보입니다. 이는 밑의 그림처럼 전체에 lock이 걸려있고, 다수의 스레드들 중에서 하나만이 while문을 통과한 후 lock을 푸는 형식으로 되어있을 때, stack 기반의 경우 while문에서 기다리는 스레드들은 락을 풀기를 기다리지만, while문을 빠져나온 스레드들은 다른 스레드들과 분기점에서 만나기를 기다리고 있기 때문에 데드락 상태에 빠지고 맙니다.
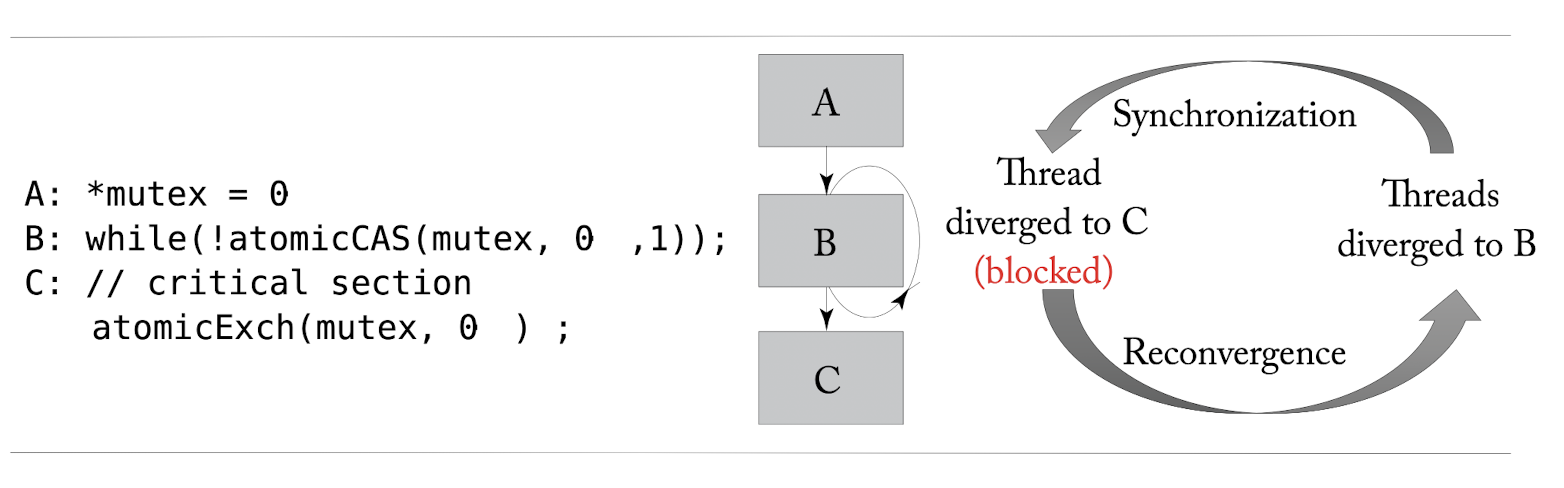
이를 NVIDIA에서는 Independent Thread Scheduling을 통해서 stackless한 재결합 매커니즘을 통해 해결하였습니다. 이는 stack을 warp convergence barrier로 대체하였습니다.
4. Memory System
GPU 계산 커널은 메모리 시스템을 통해 지시를 가져오고 저장합니다. 이러한 메모리에 CUDA와 같은 GPGPU 프로그래밍 API로 접근이 가능한데, 우리는 GPGPU 프로그래밍에서 사용되는 메모리 공간과 구조에 대해서 알아보도록 하겠습니다.
CPU는 보통 레지스터 파일과 메모리, 두개의 메모리 공간을 포함합니다. 최신 GPU들은 논리적으로 지역 메모리와 전역 메모리로 나뉘어 집니다. 지역 메모리는 스레드당 할당되는 메모리이며, register spilling(수용할 수 있는 레지스터의 개수보다 변수의 수가 더 많아 일부 변수가 메모리에 상주하게되는 경우)를 위해 사용되는 반면, 전역 변수는 멀티 스레드들 공유되는 데이터 구조를 위해 사용됩니다. 공유 메모리는 많은 프로그래머들이 어플리케이션에서 어떠한 데이터를 계산에 써야하는지 알기 떄문에, 한번에 모든 데이터를 공유 메모리로 들고와 off-chip 메모리 접근의 긴 지연 시간을 줄이고, 데이터에 대한 계산 도중 메모리에 대한 긴 접근 지연을 방지합니다. 또한 여러 번의 지시를 통해 메모리를 들고오는 것보다, 한번에 GPU와 off-chip 메모리 사이에서 이동하는 것이 적은 시간이 들며, 에너지도 적게듭니다.
4.1 First-Level Memory Structures
이번 장에서는 Scratchpad와 L1 데이터 캐시가 결합된 공유 메모리와 이들이 어떻게 코어 파이프라인에서 상호 작용하는 지를 알아보고, L1 캐시의 구조에 대해서 알아보도록 하겠습니다.
4.1.1 Scratchpad Memory and L1 Data Cache
CUDA 프로그래밍에서 공유 메모리는 작지만 지연이 적고 주어진 CTA를 통해 접근 가능한 메모리를 얘기하지만, 이는 보통 scratchpad 메모리에 해당합니다.이는 사용가능한 용량이 적기 때문에 한 스레드가 주어진 사이클을 벗어나 다른 메모리로 접근하는 bank conflict가 일어날 수도 있습니다. 먼저 이러한 공유 메모리 문제를 살펴보기 전에 L1 데이터 캐시부터 살펴보겠습니다.
L1 데이터 캐시는 전역 메모리 주소의 부분 집합을 가지고 있습니다. 만약 warp에서 L1 데이터 캐시에서 데이터 접근을 하였는데, 찾지 못한다면 더 하위 메모리로 접근하게 됩니다. 프로그래머들은 이러한 bank conflict나 cache miss 상황을 피해야만 합니다. 밑의 그림은 GPU 캐시 구조에 대해서 설명한 것으로, L1 cache와 공유 메모리가 존재하며, 그림의 중간에는 공유 메모리 접근을 위해 특정된 SRAM 데이터 배열이 존재합니다. 이는 지시 파이프라인에서 replay 매커니즘을 활용하여 멈춤없는(non-stalling) 인터페이스를 구조적으로 돕습니다. 이는 먼저 지시 파이프라인에서 1번의 L1 캐시에 메모리 접근 요청이 Load/Store 유닛에서 보내져옵니다. 이 요청은 메모리 주소와 스레드에서 실행할 작업 종류로 구성되어 있습니다.

Shared Memory Access Operations
공유 메모리 접근에 있어 결정권자는 요구된 요청이 bank conflict를 일으키는 지 여부를 결정해야 합니다. 만약 일으킨다면, 요구를 더 작은 파트로 나누어 bank conflict가 안 일어나도록 나눈 파트는 실행시키고, 일어날 만한 파트는 지시 파이프라인으로 돌려보내 다시 실행시킵니다. 이러한 뒤이어지는 실행은 replay라고 불립니다. 이는 큰 레지스터 파일에 다시 접근해야하기 때문에 자원을 소모하지만, 다시 수행하여 안전하게 수행됩니다. 자원 효율성을 따지면 replay를 제한하거나 공간이 부족하다면 메모리 접근 작업을 피하도록 합니다.
공유 메모리 요청의 수용된 부분은 3번에 해당하는 tag unit을 통과하며 공유 메모리가 맵핑된 곳을 살펴봅니다. 공유 메모리 로드 요청을 수용하면 bank conflicts의 부재로 직접 매핑된 메모리 관찰의 지연이 일정하기 때문에, 결정권자가 지시 파이프라인의 레지스터 파일에 writeback 이벤트를 스케쥴링합니다. tag unit은 스레드의 요청을 데이터 배열에서 각각의 bank로 분배하는 4번의 주소 크로스바를 제어하기 위하여 어느 bank에 메핑 시킬지를 결정합니다. 데이터 배열 안의 각각의 bank는 32 비트 크기로, 각각의 디코더가 각각의 bank에 다른 열에 접근할 수 있도록 독립적인 접근을 허용합니다. 데이터는 6번의 데이터 크로스바를 통해 레지스터 파일 안의 적절한 스레드 라인의 저장고에 돌아오게 됩니다. 해당하는 활성화된 스레드만이 레지스터 파일에 값을 씁니다.
공유 메모리 검색의 한 사이클 지연을 생각하면, replay되는 부분은 L1 캐시 결정권자에게 접근합니다. 만약 replay 부분이 bank conflict를 만나면 다시 더 나뉘어져 반복되게 됩니다.