5. The C++ memory model and operations on atomic types
무조건 참조해서 볼 것 : https://modoocode.com/271
5.1. Memory model basics
메모리 모델에는 메모리 상의 데이터 배치를 보는 기본적인 구조적(structural) 관점과 동시적(concurrency) 관점, 이렇게 2가지 관점이 있습니다. 구조적 관점이 동시성에 있어서 매우 중요한데, 저수준의 원자적 연산을 살펴볼 때는 특히나 더욱 그렇습니다.
5.1.1. Objects and memory locations
C++ 프로그램에서 모든 데이터는 객체로 이루어집니다. 객체는 타입이 무엇이든 하나 이상의 메모리 위치에 저장됩니다. 각각의 그러한 메모리 위치는 스칼라 타입의 객체일 수도 있고 인접한 비트필드의 시퀀스일 수도 있습니다. 인접한 비트필드가 별도의 객체들일지라도, 그 객체들은 여전히 같은 메모리 위치로 간주됩니다. 다음 그림은 하나의 구조체가 어떻게 여러개의 객체와 메모리 위치로 분할되는지를 보여줍니다.
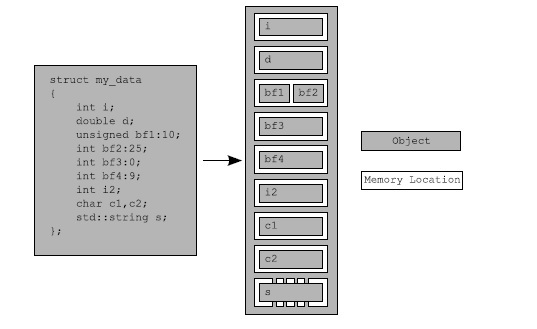
먼저 전체 구조체는 하나의 객체이며, 여러 개의 하위객체로 구성되는데, 각 데이터 멤버별로 하나씩 공간을 차지합니다. 비트 필드 bf1과 bf2는 메모리 위치를 공유하고, std::string 객체 s는 내부적으로 여러 메모리 위치로 구성되지만, 나머지 각 멤버들은 자신의 메모리 위치를 갖습니다.
- 모든 변수는 객체인데, 다른 객체의 멤버도 포함됩니다.
- 모든 객체는 적어도 1개의 메모리 위치를 점유합니다.
- int 혹은 char와 같은 기본타입 변수는 그 크기가 무엇이든, 배열의 일부분이든 정확히 1개의 메모리 위치를 가집니다.
- 인접한 비트 필드는 같은 메모리 위치의 일부분입니다.
5.1.2. Objects, memory locations, and concurrency
2개의 thread에서 하나의 메모리에 동시에 접근하면 경쟁 조건이 발생하여 문제가 생깁니다. 경쟁 조건을 피하기 위해서는 2개의 thread들에서의 접근 사이에 강제된 순서(enforced ordering)가 필요합니다. 정의된 순서를 확실하게 하는 한가지 방법은 뮤텍스를 사용하는 것입니다. 다른 방법으로는 원자적 연산의 동기화 특성을 사용하는 것입니다. 이러한 강제된 순서가 존재하지 않는다면 경쟁 조건으로 들어가 미정의 행동을 취하게 됩니다.
5.1.3. Modification orders
C++ 프로그램안의 모든 객체는 프로그램 내의 모든 thread들로부터 객체의 초기화로 시작되는 해당 객체에 대한 모든 쓰기로 구성된 정의된 변경 순서를 가집니다. 대부분의 경우 이 순서는 프로그램 실행시마다 달라지지만, 주어진 실행 시점에서는 시스템의 모든 thread가 그 순서에 동의해야만 합니다. 만약 이를 어긴다면 하나의 변수에 대해서 경쟁 상태에 돌입하여 미정의 행동을 발생시킵니다.
이는 추측에 근거한 실행이 허용되지 않음을 의미하는데, 왜냐하면 한 thread가 변경 순서내의 특정 시점에 있다면, 그 thread로부터의 다음번 읽기는 나중 값을 리턴해야만 하고, 그 thread로부터 해당 객체에 대한 다음번 쓰기는 그 변경 순서에서 나중에 발생해야만 하기 때문입니다. 또한 같은 thread에서 한 객체에 대한 쓰기 다음의 읽기는 그 쓰여진 값 혹은 그 객체의 변경 순서에서 나중에 발생한 또다른 값을 리턴해야만 합니다. 비록 프로그램 내에서 모든 thread는 각각의 개별 객체의 변경 순서에 동의해야 하지만, 분리된 객체들에 대한 상대적 연산 순서에는 동의할 필요는 없습니다.
5.2. Atomic operations and types in C++
원자적 연산(atomic operation)은 더이상 나눌수 없는 연산입니다. 시스템의 어떠한 스레드로부터도 반쯤만 완료된 원자적 연산을 볼 수는 없습니다. 원자적 연산은 완료되거나 완료되지 않거나 둘 중 하나입니다. 만약 객체의 값을 읽는 로딩 연산이 원자적이면, 그 객체에 대한 모든 변경 또한 원자적입니다. 로딩은 그 객체의 초기값 아니면 변경 연산중의 하나에 의해 저장된 값을 보여줄 것입니다.
원자적 계산이 아닌 계산을 수행한다면 값이 바뀌고 있는 도중의 값을 리턴하며 이는 간단한 문제를 가진 경쟁 조건을 가지게 됩니다.
5.2.1. The standard atomic types
원자적 타입의 모든 연산들은 원자적이고, 비록 여러분이 뮤텍스를 이용한 보통의 연산들이 원자적으로 보이게끔 할 수도 있지만, 오직 원자적 타입에 대한 연산들만이 언어 정의 차원에서 원자적입니다. 사실 표준 원자적 타입은 거의 모두 is_lock_free() 멤버함수를 가지고, 이것은 여러분이 주어진 타입에 대한 연산이 원자적 명령문으로 직접 이루어지는지(is_lock_free()가 true를 리턴하면), 아니면 컴파일러와 라이브러리 내부에서 잠금을 사용하는지(is_lock_free()가 false를 리턴하면)를 알려주며 자체적인 에뮬레이션을 돌립니다.
이를 아는 것은 중요한데, 원자적 타입을 쓰는 이유가 mutex 기반 동기화를 대체하기 위함인데, 원자적 연산에 내재된 뮤텍스가 존재한다면 이는 큰 의미를 지니지 않을 것입니다.
다양한 정수 타입에 대해 원자적 타입이 lock-free인지 컴파일 타임에 알려주는 매크로를 라이브러리에서 제공합니다. C++17 이후로는, 모든 원자적 타입은 static constexpr 멤버 변수를 가지며 X::is_always_lock_free는 모든 하드웨어에서 X의 lock-free 여부를 알려준다. 또한 특정 빌트인 타입들과 그들의 unsigned 타입들을 위한 원자적 타입들의 lock-free 상태를 ATOMIC_{TYPE_NAME}_LOCK_FREE를 통해 명시 가능합니다. 이때 값이 0이라면 lock-free가 될 수 없으며, 2라면 항상 Lock-free이고 1이면 런타임에 따라 lock-free일수도 아닐 수도 있습니다.
is_lock_free() 멤버함수를 제공하지 않는 유일한 타입은 std::atomic_flag로 간단한 boolean 플래그인데, 이 타입에 대한 연산들은 lock-free이어야만 한다. 이는 간단한 lock을 시행하고 모든 다른 원자적 타입의 기반처럼 수행하는데 사용됩니다.
나머지 원자적 타입들은 모두 std::atomic<> 클래스 템플릿의 특수화를 통해 접근되며 좀 더 기능적이지만 lock-free가 아닐 수도 있습니다. 대부분의 대중적인 플랫폼에서는 내장 타입에 대한 원자적 타입들은 대체로 lock-free이지만 필수는 아닙니다.
std::atomic<> 클래스 템플릿을 직접적으로 사용하여 다른 이름으로 atomic_{TYPE}형태로도 사용이 가능합니다. 또한, std::atomic<> 클래스 템플릿은 단순히 템플릿 특수화만은 아니라 주 템플릿을 있어, 사용자 정의 타입에 대한 원자적 타입을 만드는데도 사용될 수 있습니다.
기본 원자적 타입들은 복사 생성자 및 복사 할당자가 없기에 복사 및 할당 불가능하지만, load(), store(), exchange(), compare_exchange_weak(), compare_exchange_strong()으로 암시적 변환 및 할당을 지원하며 연산자들은 이들에 제한되게 됩니다. 또한 산술적 연산도 지원하며, 이에 해당하는 fetch_add() 및 fetch_or()과 같은 멤버 함수를 가집니다. 할당 연산자 및 멤버 함수의 변환 값은 저장된 값 혹은 작업 전 값인데 참조를 반환하지 않아 잠재적인 문제를 미리 방지합니다. std::atomic<> 클래스 템플릿은 특수화된 집합이 아니며, 사용자 정의 타입에 대해 원자적 행동을 하도록 하는 기본 템플릿도 가지고 있습니다. 이 경우 메서드는 load(), store(), exchange(), compare_exchange_weak(), compare_exchange_strong() 및 사용자 정의 유형으로의 할당 및 변환으로 제한됩니다.
원자적 타입에 대한 동작은 선택적인 memory_order 목록의 값 중 하나를 memory ordering 인자로서 받습니다. 이를 통해 요구되는 memory-ordering 의미를 특정합니다. 이는 수행하는 일에 따라 사용되는 인자들이 바뀝니다.
- Store operation : memory_order_relaxed, memory_order_release, memory_order_seq_cst
- Load operation : memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_seq_cst
- Read-modify-write operation : memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_seq_cst, memory_order_acq_rel
5.2.2. Operations on std::atomic_flag
std::atomic_flag는 가장 간단한 표준 원자 타입으로, boolean 로 표현됩니다. 이 객체는 set과 clear, 2개 상태 중의 하나가 됩니다. std::atomic_flag의 객체는 ATOMIC_FLAG_INIT로 초기화되어야만 하며 이는 플래그를 항상 clear 상태로 초기화되도록 합니다.
std:atomic_flag f = ATOMIC_FLAG_INIT;이처럼 원자적 타입만이 위와 같은 초기화를 위한 특별한 작업을 요구하지만, lock-free를 보장하는 유일한 타입입니다. 만약 정적으로 저장되어 있다면 정적으로 초기화되는데, 이는 초기화 순서의 문제 없이 항상 처음 처음 사용될 때 초기화됩니다.
flag 객체가 초기화되면 파괴되거나, clear하거나, set하여 이전 값을 묻는 3가지 동작을 수행할 수 있습니다. 이들은 각각 소멸자, clear() 멤버 함수, test_and_set() 멤버 함수에 해당합니다.
또한, std::atomic_flag 객체를 복사 생성 및 할당할 수 없는데 이는 원자적 타입에 대한 모든 작업은 원자적이어야만 하며, 한 값에 대해 두개의 객체가 서로 작업을 수행하려고 하는 경우는 비원자적인 작업에 행동하기 때문입니다. std::atomic_flag의 제한된 특징은 스핀락 뮤텍스 사용에 이상적입니다.
Listing 5.1 Implementation of a spinlock mutex using std::atomic_flag
#include <atomic>
class spinlock_mutex
{
std::atomic_flag flag;
public:
spinlock_mutex():
flag(ATOMIC_FLAG_INIT)
{}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};std::atomic_flag는 너무 제한적이며, 위의 예시 처럼 busy-wait을 lock 안에서 수행하기에 일반적인 Boolean 플래그로는 사용될 수 없어, 수정하지 않는 간단한 질의 연산을 가지지 않기에 std::atomic<bool>이 선호됩니다. (값을 볼 수 없다는 뜻입니다)
5.2.3. Operations on std::atomic<bool>
가장 기본적인 원자적 정수 타입은 std::atomic<bool>입니다. 이전의 std::atomic_flag보다 더 많은 기능을 가지지만 여전히 복사 및 할당이 불가능합니다. 비원자적 bool로부터 생성될 수 있으므로, 초기값으로 true 혹은 false가 될 수 있습니다.
std::atomic<bool> b(true);
b = false;비원자적 bool로부터의 할당 연산자는 할당된 객체를 가리키는 참조자를 리턴하는 일반적인 관례와는 다르게 원자적 타입에서는 흔하게 할당된 값을 가지는 타입을 리턴합니다. 만약 참조된 원자적 변수가 리턴된다면, 결과를 할당 받는 코드에 명시적으로 값을 가져오는 경우 다른 thread에 의해 값이 변경될 가능성을 지니게 되기에, 비원자적인 값을 리턴하는 것으로 이를 사전에 예방합니다.
이전의 atomic_flag에서의 clear 대신에 memory-order이 특정지어 질 수 있는 store() 함수를 불러서 값을 쓸 수 있으며, 비슷하게, test_and_set()은 좀 더 이전 값을 원자적으로 가져오고 새로운 값을 저장하여 좀 더 일반적으로 사용 가능한 exchange()로 대체 가능합니다. 또한 bool로의 암묵적 변환과 명시적 load를 통해 수정이 필요없는 쿼리를 지원합니다. exchange는 읽기-수정-쓰기 작업을 수행합니다. 이는 유일한 읽기-수정-쓰기 작업이 아닙니다.
[Storing a New Value (Or not) Depending On the Current Value]
원자적 타입 프로그래밍의 주춧돌이 되는 함수로, 원자적 변수를 제공된 예상값과 비교하여 만약 그들이 같다면 제공된 목적값을 저장하고 그렇지 않다면 예상 값이 원자적 변수의 값으로 업데이트하는 함수들을 비교 교환 함수라 불리며, compare_exchange_weak()와 compare_exchange_strong()가 멤버 함수로 존재합니다. 이 함수들의 리턴 타입은 bool인데, 저장이 수행되면 true를 그렇지 않으면 false를 리턴합니다.
compare_exchange_weak() 함수에서는 비록 원래값과 예상값이 같다고 하더라도 저장이 되지 않을 수가 있는데, 이 경우 변수의 값은 변경되지 않고 리턴값은 false가 됩니다. 이는 단일한 compare-exchange 명령어가 없는 기계에서 발생할 수 있는데, 프로세서가 그 연산이 원자적으로 수행됨을 보장할 수 없기 때문입니다. 연산을 수행하는 스레드가 명령어들을 수행하는 중간에 시스템에 의해 다른 스레드로 스케쥴링되면 발생할 수 있는데 이를 거짓된 실패(spurious failure)라 부릅니다. compare_exchange_weak()는 거짓된 실패가 발생할 수 있으므로, 보통은 루프안에서 사용되어야 한다.
bool expected = false;
extern atomic<bool> b; // 다른 어딘가에서 설정됨
while (!b.compare_exchange_weak(expected, true) && !expected);반면에 compare_exchange_strong()은 오직 실제값이 expected값과 다른 경우에만 false를 리턴함을 보장합니다. 이는 위와 같이 여러분이 변수를 성공적으로 변경했는지의 여부 혹은 다른 스레드가 먼저 변경했는지의 여부를 알고자 하는 루프가 필요하지 않습니다.
다른 thread에 의해 값이 변경되지 않고 싶다면, 위 두 함수 중에서 선택을 해야하는데, compare_exchange_weak()의 경우는 값의 계산이 간단한 경우에 이중 루프 문을 피하기 위해 사용하기 좋으며, 값의 계산이 복잡하다면 compare_exchange_strong을 사용하여 값을 다시 계산하는 경우가 없도록 하는 것이 좋습니다.
compare/exchange 함수는 또한 2개의 메모리 순서 인자를 취한다는 점에서 특이합니다. 이것은 성공적인 호출이 memory_order_acq_rel 시맨틱을 갖는 반면 실패한 호출은 memory_order_released 시맨틱을 갖는 것이 바람직합니다. 실패한 경우 저장하지 않으므로 memory_order_release 또는 memory_order_acq_rel 의미론을 가질 수 없습니다. 또한 실패에 대해 성공보다 더 엄격한 메모리 순서를 제공할 수 없습니다. 실패에 대해 memory_order_acquire 또는 memory_order_seq_cst을 원한다면 성공을 위한 메모리 순서도 지정해야 합니다.
실패 순서를 지정하지 않으면 release 부분이 제거된 성공 순서와 동일한 것으로 간주됩니다. 둘 다 지정하지 않으면 일반적으로 memory_order_seq_cst로 기본값이 지정되므로 성공 및 실패에 대한 전체 순차적 순서가 제공됩니다. compare_exchange_weak()에 대한 다음 두 호출은 동일합니다.
bool expected;
atomic<bool> b;
b.compare_exchnage_weak(expected, true, memory_order_acq_rel, memory_order_acquire);
b.compare_exchnage_weak(expected, true, memory_order_acq_rel);std::atomic<bool>과 std::atomic_flag 사이의 한가지 현격한 차이는 std::atomic<bool>은 lock-free상태가 아닐 수도 있다는 것입니다. 이를 구현하기 위해서는 연산의 원자성을 확보하기 위해 내부에서 뮤텍스를 획득해야만 할 수도 있습니다.
5.2.4. Operations on std::atomic<T*>: pointer arithmetic
T에 대한 포인터의 원자적 형태는 std::atmoic<T*>입니다. 마찬가지로, 복사 생성, 복사 할당은 되지 않지만 생 포인터 값에서의 생성 및 할당은 가능합니다. 이 외로도 앞서 std::atomic<bool>에서 언급한 메서드를 가지고 있으며 리턴 타입만 다릅니다.
std::atomic<bool>과 다른 점은 포인터의 산술적 연산을 지원한다는 점입니다. fetch_add() 및 fetch_sub() 멤버 함수로 기본적인 연산 및 +=, -=, ++, --이 사용 가능합니다. fetch를 사용한 경우 원래 값을 리턴하지만, 연산자를 이용한 경우는 변경된 값을 리턴합니다. 이러한 작업은 exchange()와 동일한 읽기-수정-쓰기 작업에 해당합니다.
fetch를 쓰는 경우, memory-ordering 의미를 추가 인자로 넘길 수 있으며, 읽고 쓰기를 모두 수행하기에 모든 종류를 받을 수 있습니다. 하지만 오버로딩된 연산자에 대해서는 지정된 포멧이 존재하기 때문에 memory_order 지정이 불가능하고 무조건 std::memory_order_seq_cst로 고정됩니다.
5.2.5. Operations on standard atomic integral types
정수형 인자에 대한 std::atomic은 앞서 말한 동작 외에도 fetch_and, fetch_or, fetch_xor과 같이 복잡한 비트연산 혹은 전후위 연산자를 제공합니다. 하지만 곱하기 나누기, 쉬프트 연산은 불가능하며 필요하면 compare_exchange_strong으로 구현해야 합니다.
5.2.6. The std::atomic<> primary class template
사용자 정의 타입 UDT에 대한 std::atomic<UDT>은 std::atomic<bool>에서의 동일한 인터페이스를 가지지만 이를 사용하기 위해서는, 이 타입은 사소한(trivial) 복사-할당 연산자를 가져야만 합니다. 이는 이 타입이 어떠한 가상 함수 혹은 가상 기반 클래스도 가져서는 안되고 컴파일러가 생성하는 복사-할당 연산자를 가져야 한다는 것을 의미합니다. 그뿐만 아니라, 모든 기반 클래스와 비정적 데이터 멤버들도 모두 사소한 복사-할당 연산자를 가져야만 합니다. 이것은 컴파일러가 memcpy() 혹은 할당 연산을 위한 동등한 연산을 사용하도록 해야 하기 때문이다.(virtual 함수나 상속의 경우는 가상 함수 테이블이 작동하여 함수 실행에 문제가 발생할 수 있습니다) 그리고 compare-exchange 작업을 수행할 때는 비교 연산자 대신 memcmp와 같이 비트 단위로 비교를 수행합니다. 이는 함수에게 값에 대한 접근을 넘겨주는 것과 이중 lock으로 인한 데드락을 방지합니다.
일반적으로 std::atomic<UDT> 에 대한 lock-free 코드를 생성할 수 없어 모든 작업에 내부 잠금을 사용해야 하는데 내부 잠금 안의 데이터에 대해 참조나 포인터를 유출하면 안됩니다. 이를 막기 위해서 default 복사 할당 또는 비교 연산자만 합니다. 또한 라이브러리는 필요한 모든 원자적 작업에 대해 단일 잠금을 사용할 수 하여 데드락이 발생할 수 있기에 막습니다. 마지막으로, 이러한 제한은 UDT가 원시 바이트 집합으로 처리될 수 있게 하여 컴파일러가 std::atomic<UDT>에 대한 원자 명령어를 직접 사용할 수 있는 가능성을 증가시킵니다.
내장된 부동 소수점 유형이 memcpy 및 memcmp와 함께 사용할 수 있는 기준을 충족하기 때문에 std::atomic<float> 또는 std::atomic<double>을 사용할 수 있지만 compare_exchange_strong의 경우 작업이 이상하게 됩니다. 이는 부동 소수점 값에는 원자적 산술 연산이 없어 동일 비교 연산자가 정의된 원자적 사용자 정의 유형에서 작업을 수행하는 것과 같습니다. 이는 해당 연산자가 memcmp를 사용한 비교와 다르기 때문에, 같은 값이라도 다른 표현을 가져 작업이 실패할 수 있습니다.
UDT가 int 크기와 같은 경우는 원자적인 계산이 지원되지만 더 커진다면 하지 않게 됩니다. 따라서 atomic<T>의 용도로는 객체 카운터, 플래그, 포인터 혹은 간단한 데이터로 이루어진 배열 정도의 범위에서 사용 가능합니다. 이것보다 더 복잡한 자료구조나 더 복잡한 연산에서는 mutex를 쓰는 것이 낫습니다.
5.2.7. Free functions for atomic operations
지금까지 원자적 타입의 멤버 함수에 대해서만 얘기를 하였다면, 비멤버 함수도 동등하게 존재합니다. 대부분의 경우 atomc_ 접두사가 붙어 std::atomic_load()와 같이 구성됩니다. 이러한 함수들은 원자적 타입에 대해서 각각 오버로딩되어 있습니다. 메모리 태그를 지정 여부에 따라 두가지 종류의 함수가 존재합니다.
std::atomic_store(&atomic_var, new_value)
std:atomic_store_explicit(&atomic_var, new_value, std:memory_order_release)멤버 함수에 의해 참조되는 원자 객체는 암묵적인 반면, 모든 비멤버 함수는 원자 객체에 대한 포인터를 첫 번째 매개 변수로 가져갑니다.
이러한 함수들은 C 호환이 되도록 설계되어 있으므로 모든 경우에 참조보다는 포인터를 사용해야 합니다. std::atomic_flag에 대한 연산은 std::atomic_flag_test_and_set(), std::atomic_flag_clear()라는 이름으로 플래그 부분을 기술한다는 점에서 특이점을 지닙니다. 메모리 순서를 다시 지정하는 추가 변형은 _explicit 접미사를 갖습니다.
C++ 표준 라이브러리는 또한 shared_ptr의 인스턴스에 원자적으로 접근하기 위한 비멤버 함수를 제공하여 원자적 형식이 아니지만 원자적 연산을 지원합니다. 사용할 수 있는 원자 연산은 load, store, exchange로 표준 원자 유형에 대한 동일한 연산의 오버로드로 제공되며, 첫 번째 인수로 std::shared_ptr<>*를 사용한다.
std::shared_ptr<my_data> p;
void process_global_data()
{
std::shared_ptr<my_data> local=std::atomic_load(&p);
process_data(local);
}
void update_global_data()
{
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p,local);
} 다른 유형의 원자 연산과 마찬가지로 _explicit 변형이 제공되어 원하는 메모리 순서를 지정할 수 있으며 std::atomic_is_lock_free() 함수를 사용하여 구현이 원자성을 보장하기 위해 잠금을 사용하는지 확인할 수 있습니다.
Concurrency TS는 또한 원자적 유형인 std::experimental::atomic_shared_ptr<T>를 제공합니다. std::atomic<UDT>와 동일한 연산 집합을 제공합니다. 일반 std::shared_ptr 인스턴스에 추가 비용을 부과하지 않는 잠금 없는 구현을 허용하기 위해서 별도의 유형으로 구현되었는데, std::atomic 템플릿과 마찬가지로, is_lock_free 멤버 함수로 테스트할 수 있는 lock-free 인지를 확인 해야합니다. 만약 lock-free가 아니더라도, 원자적 연산을 사용할 예정이라면 원자적 함수를 따로 쓰지 않아도 되는 원자적 타입 버전을 사용하는 것이 좋습니다. 원자 유형 및 연산의 모든 용도와 마찬가지로, 잠재적인 속도 향상을 위해 원자 유형을 사용하는 경우, 다른 동기화 메커니즘을 사용하여 비교해보는 것이 중요합니다.
5.3. Synchronizing operations and enforcing ordering
두 개의 스레드가 있고, 첫번째 스레드는 두번째 스레드에 의해 읽혀질 데이터를 추가한다고 해봅시다. 문제의 경쟁 상태를 피하기 위해, 첫번째 스레드는 데이터가 준비되었음을 알리기 위해 플래그를 설정하고, 두번째 스레드는 그 플래그가 설정되기 전까지는 데이터를 읽지 않기로 합니다.
Listing 5.2 Reading and writing variables from different threads
std::vector<int> data;
std::atomic<bool> data_ready(false);
void reader_thread()
{
while (!data_ready.load()) { <- (1)
std::this_thread::sleep(std::chrono::milliseconds(1));
}
std::cout << "The answer = " << data[0] << std::endl; <- (2)
}
void writer_thread()
{
data.push_back(42); <- (3)
data_ready = true; <- (4)
}효율성은 일단 생각하지 않으면, 스레드 간의 데이터 공유가 비현실적으로 되지 않게 하려면, 모든 데이터 항목들이 원자적이 되도록 강제되야 합니다. 강제된 순서 없이 동일한 데이터에 접근하는 비원자적 읽기(2)와 쓰기(3)는 정의되지 않은 행동이므로, 이것이 동작하게 만들기 위해서는 어딘가에 강제된 순서가 있어야만 합니다.
요구되는 강제적인 순서는 data_ready에 대한 연산 때문에 발생합니다. 이들 연산은 메모리 모델 관계인 happens-before와 synchronizes-with에 의해 필요한 순서를 제공합니다. 두 함수에서 데이터 쓰기는 플래그에 쓰기 전에 발생하고, 플래그 읽기는 데이터 읽기 전에 발생합니다(happens-before). data_ready에서 읽은 데이터가 true이면, 쓰기는 그 읽기와 동기화되는데(synchronizes-with), 이는 happens-before 관계를 생성합니다. happens-before는 추이관계이기 때문에, 데이터 쓰기는 플래그 쓰기 전에 발생하는데, 이는 플래그로부터 true값을 읽기 전에 발생하고, 이는 데이터 읽기 전에 발생하므로, 여러분은 강요된 순서를 가지게 됩니다.
앞서 말한 synchornizes-with과 happens-before가 어떤 것을 의미하는 지 알아보겠습니다.
5.3.1. The synchornizes-with relationship
synchronizes-with 관계는 원자적 타입에 대한 연산들 사이에서만 얻을 수 있습니다. 뮤텍스 잠금과 같은 데이터 구조체에 대한 연산도 만약 그 데이터 구조체가 원자적 타입을 포함한다면 이 관계를 제공할 수 있는데 그 데이터 구조체에 대한 연산들은 내부적으로 적당한 원자적 연산을 수행하지만 근본적으로 이 관계는 원자적 타입에 대한 연산에 기인합니다.
기본 개념은 다음과 같습니다. 변수 x에 대한 적절하게 태그된 원자적 쓰기 연산 W는 x에 대한 그 값을 읽는 적절하게 태그된 원자적 읽기 연산과 동기화된다고 합니다(synchronizes-with). 이 때 읽혀지는 값은 쓰기(W)에 의한 값일 수도 있고, 초기의 쓰기(W)를 수행한 스레드에서 나중에 원자적 쓰기 연산에 의한 값일 수도 있고, 혹은 어떠한 스레드에서도 x에 대한 뒤따르는 원자적 읽기-변경-쓰기 연산(fetch_add() 혹은 compare_exchange_weak())에 의한 값일 수도 있습니다.
즉, 한 스레드에서 쓴 것을 다른 스레드에서 읽으면 그 둘 스레드에서 이루어진 작업은 동기화되었다고 할 수 있습니다.
5.3.2. The happens-before relationship
happens-before 관계는 프로그램에서 연산 순서의 기본 구성 요소로, 어떤 연산이 다른 어떤 연산의 결과를 볼수 있는 가를 명시합니다. 단일 스레드에서는 이것이 명백합니다. 소스코드 상에서 하나의 연산(A)이 다른 연산(B)보다 앞선 문장에 나타난다면, A는 B 이전에 발생합니다(happens-before). 만약 밑의 예시에서 연산이 같은 문장에 나타난다면, 일반적으로는 그들 사이에는 happens-before 관계는 없습니다.
Listing 5.3 Order of evaluation of arguments to a function call is unspecified
#include <iostream>
void foo(int a,int b)
{
std::cout<<a<<","<<b<<std::endl;
}
int get_num()
{
static int i=0;
return ++i;
}
int main()
{
foo(get_num(),get_num());
}기본 수준에서, 스레드간 happens-before 관계는 상대적으로 간단하고 synchronizes-with 관계에 의존하게 된다.
일반적으로, 단일 문 내에서의 순서는 매겨지지 않으며, 이들은 다음 문으로 넘어가기 전에 모두 수행됩니다. 스레드들 간의 상호작용이 나오면 복잡해지는데, 한 스레드 간 스레드에서의 작업 A가 다른 스레드에서의 작업 B보다 먼저 발생한다면, A는 B보다 먼저 발생하지만 이는 스레드 간의 happens-before에서는 유효하지 않지만 중요합니다.
기본 수준에서 스레드 간의 happend-beofer은 비교적 단순하며 synchronized-with 관계에 의존하는데, 만약 한 스레드에서의 연산 A가 다른 스레드에서의 연산 B와 동기화된다면(synchronizes-with), A는 스레드간 B 이전에 발생합니다(inter-thread happens-before). 이것은 추이 관계(transitive)이며, 연결되며 일어날 수 있습니다.
만약 A가 B와 스레드간 happens-before 관계이고, B가 C와 스레드간 happens-before 관계라면, A는 C와 스레드간 happens-before 관계가 된다.
strongly-happens-before 관계는 조금 다르지만 대부분의 경우 똑같습니다. 위에서 설명한 것과 동일한 두 규칙이 적용됩니다. 차이점은 memory_order_consume로 태그된 연산은 inter-thread happens-before에 참여하지만 strongly-happens-before 관계에서는 참여하지 않는다는 것입니다. 대부분의 코드는 memory_order_consume를 사용하지 않아야 하므로, 이러한 차이는 실제로 영향을 미치지 않습니다.
5.3.3. Memory ordering for atomic operations
원자 타입에 대한 연산에 적용될 수 있는 메모리 순서 옵션은 6개 존재합니다.
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_req_cst
순차적 일관된 순서, 획득-해제 순서, 그리고 완화된 순서로 비록 옵션 수가 6개 이지만, 이들은 3개의 모델을 나타냅니다. 이러한 메모리 순서 모델들은 서로 다른 CPU 아키텍쳐 상에서의 비용이 차이를 보일 수 있습니다. 예를 들어, 프로세서에 의해 연산의 가시성의 미세 조정이 가능한 아키텍쳐를 기반으로 하는 시스템 상에서, 획득-해제 순서 혹은 완화된 순서에 비해 순차적 일관된 순서가 추가적인 동기화 명령들을 요구할 수 있고, 완화된 순서에 비해 획득-해제 순서가 명령을 더 요구할 수 있습니다. 만약 이들 시스템들이 많은 프로세서들을 가진다면, 이들 추가적인 동기화 명령들은 상당한 양의 시간이 걸릴 수 있으며, 이는 전체적인 시스템 성능을 하락시킬 수 있습니다.
이러한 모델들의 이용은 잘 정제된 순서 관계의 성능 향상을 누릴 수도 있습니다. 따라서 어떠한 경우 어떠한 메모리 모델을 써야하는 지 알아두어야만 합니다.
[순차적 일관성 순서(Sequentially Consistent Ordering)]
기본 순서는 순차적으로 일관된 것으로 이름지어졌는데, 이는 프로그램의 행동이 세상의 간단한 순차적 관점과 일치하기 때문입니다. 가장 이해하기 쉬운 메모리 순서로, 모든 스레드들은 똑같은 순서의 연산들을 봐야만 하기에 연산들이 재정렬될 수 없음을 의미합니다.
동기화 관점에서 보자면, 순차적으로 일관된 store은 그 저장된 값을 읽는 동일한 변수의 순차적으로 일관된 load와 synchronizes-with됩니다. 이는 2개 이상의 스레드들의 연산에 한가지 순서 제약을 제공하는데, 순차적 일관성이 이보다 더 강력하다. load 이후에 행해지는 모든 순차적으로 일관된 원자적 연산들은 또한 순차적으로 일관된 원자적 연산들을 사용하는 시스템 내의 다른 스레드들에게 store 이후에 나타나야만 한다.
이렇게 이해하기 쉽고 강력하기에 비용 또한 비쌉니다. 프로세스 간의 모든 작업들의 순서가 지켜져야 하며, 동기화 작업 그 이상의 것이 필요하기 때문입니다. 이는 성능적인 면에서는 별로 추천될 수 없습니다.
Listing 5.4 Sequential consistency implies a total ordering
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_seq_cst);
}
void write_y()
{
y.store(true,std::memory_order_seq_cst);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_seq_cst));
if(y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_seq_cst));
if(x.load(std::memory_order_seq_cst))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
이는 순서가 지켜지기 때문에, z가 0이 되는 경우의 수는 존재하지 않으며, 반드시 write_x가 진행되고 나서야 read_x_then_y가 진행되며 write_y가 진행되고 나서야 read_y_then_x가 진행되기 때문에 z의 값이 적어도 1은 오르게 됩니다.
하지만 이러한 값비싼 동기화 연산을 모두 적용시킬 수 없기에 다른 메모리 모델들도 필요로 됩니다.
[비순차적 일관성 순서(Non-Sequentially Consistent Memory Orderings)]
순차적 일관성 세계를 벗어나면, 복잡해지기 시작하는데, 이해해야 할 가장 큰 사실은 작업들의 통일된 전역 순서는 더이상 없다는 점입니다. 이는 동일한 연산들에 대해 다른 스레드는 다른 순서를 볼 수 있고, 스레드는 이벤트의 순서에 대해 동의할 필요가 없다는 점입니다. 이는 제약이 없어졌기 때문에 컴파일러만이 명령어 순서를 바꾸는 것이 아니라 스레드들도 같은 코드를 동작시키더라도 CPU 캐시와 내부 버퍼에 따라 순서가 바뀝니다. 다른 순서 제약이 없는 경우, 유일한 강제 조건은 모든 스레드가 각각의 변수에 대한 변경 순서는 동의한다는 점입니다. 표시되는 값이 순서만 따른다면 같은 시간이라도 스레드마다 다른 값을 지닐 수 있습니다.
[완화된 순서(Relaxed Ordering)]
완회된 순서로 수행되는 원자 타입의 연산은 synchronizes-with 관계를 가지지 않습니다. 단일 스레드내의 같은 변수에 대한 연산은 여전히 happens-before 관계에 복종하지만, 다른 스레드에 관련된 순서에는 관여하지 않으며, 유일한 요구 사항은 같은 스레드로부터 단일 원자적 변수에 대한 접근은 재배치되지 않는다는 것이다. 추가적인 동기화 없이, 각 변수의 변경 순서는 memory_order_relaxed를 사용하는 스레드들 간에서 유일하게 공유됩니다.
Listing 5.5 Relaxed operations have few ordering requirements
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_relaxed);
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed));
if(x.load(std::memory_order_relaxed))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0);
}이는 assert문에서 에러가 발생할 수 있는데, write_x_then_y에서의 문장들이 자유롭게 재배치되어 x가 false인데 y가 true있으며, y를 load하기 전에 x가 먼저 load될 수도 있습니다. 한 스레드 안에서 변수에 묶여 있는 모든 happens-before 관계를 따르기만 한다면 자유롭게 재배치될 수 있어 완화된 연산은 synchronizes-with 관계를 가지지 않습니다.

Listing 5.6 Relaxed operations on multiple threads
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<int> x(0),y(0),z(0);
std::atomic<bool> go(false);
unsigned const loop_count=10;
struct read_values
{
int x,y,z;
};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(std::atomic<int>* var_to_inc,read_values* values)
{
while(!go)
std::this_thread::yield();
for(unsigned i=0;i<loop_count;++i)
{
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
var_to_inc->store(i+1,std::memory_order_relaxed);
std::this_thread::yield();
}
}
void read_vals(read_values* values)
{
while(!go)
std::this_thread::yield();
for(unsigned i=0;i<loop_count;++i)
{
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v)
{
for(unsigned i=0;i<loop_count;++i)
{
if(i)
std::cout<<",";
std::cout<<"("<<v[i].x<<","<<v[i].y<<","<<v[i].z<<")";
}
std::cout<<std::endl;
}
int main()
{
std::thread t1(increment,&x,values1);
std::thread t2(increment,&y,values2);
std::thread t3(increment,&z,values3);
std::thread t4(read_vals,values4);
std::thread t5(read_vals,values5);
go=true;
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1);
print(values2);
print(values3);
print(values4);
print(values5);
}위의 함수의 경우는 x, y, z를 t1, t2, t3에서 증가 시키고 이를 5군데에서 써넣습니다. 이때 t1, t2, t3는 각각 x,y,z에 대해서 store과 load를 모두 수행하기에, 각각 해당하는 값은 순서대로 올라가지만 나머지 두 값은 무작위로 올라갑니다. 다른 t4, t5의 경우는 올라가는 값이 무작위로 산출됩니다. 이러한 결과는 유일하지 않으며 t1, t2, t3에서의 x, y, z 값들만이 유일하게 보장됩니다. 이는 싱글 스레드에서의 원자적 연산에 대한 동기화는 보장되어 있기 때문입니다.
[획득-해제 순서(Acquire-Release Ordering)]
획득-해제 순서는 완화된 순서보다 정렬되어 획득-해제 순서에는 여전히 전체 순서는 없지만 몇가지 동기화를 가지고 있습니다. 이 순서 모델 하에서, 원자적 읽기는 획득(acquire) 연산이고(memory_order_acquire), 원자적 쓰기는 해제(release) 연산이고(memory_order_release), 원자적 읽기-변경-쓰기 연산은 획득 혹은 해제 혹은 둘다에 해당합니다(memory_order_acq_rel). 동기화는 해제하는 스레드와 획득하는 스레드 사이에서의 쌍으로 이루어집니다. 해제 연산은 쓰여진 값을 읽는 획득 연산과 동기화됩니다(synchronizes-with). 이는 다른 스레드들은 여전히 다른 순서들을 보지만, 이들 순서는 제한되어 있음을 의미합니다.
Listing 5.7 Acquire-release doesn't imply a total ordering
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_release);
}
void write_y()
{
y.store(true,std::memory_order_release);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_acquire));
if(y.load(std::memory_order_acquire))
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_acquire))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
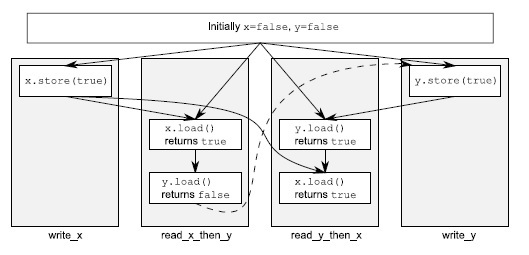
이번 경우, assert가 발생할 수 있는데, 이는 if문의 x의 load와 y의 load 모두가 false를 읽을 가능성이 존재하기 때문입니다. x와 y는 서로 다른 스레드에서 쓰여지므로, 메모리 공유가 제대로 되지 않는 경우, 각 경우의 해제에서 획득까지의 순서는 다른 스레드에서의 연산에 아무런 영향도 미치지 않기 때문입니다. 밑의 그림은 이에 대한 것은 대략적으로 보여줍니다.

획득-해제 순서의 이점을 보려면, 2개의 저장을 같은 스레드에서 해야만 합니다. y에 대한 저장을 memory_order_release로 하고, y의 읽기를 memory_order_acquire로 하면, 실제로 x에 대한 연산에 순서를 부과할 수 있게 됩니다.
Listing 5.8 Acquire-release operations can impose ordering on relaxed operations
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); <-- (1)
y.store(true, std::memory_order_release); <-- (2)
}
void read_y_then_x()
{
while (!y.load(std::memory_order_acquire)); <-- (3)
if (x.load(std::memory_order_relaxed)) <-- (4)
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); <-- (5)
}
결국 y의 load는 store에 의해 쓰여진 대로 true를 볼 것이다. 저장은 memory_order_release를 사용하고, 읽기는 memory_order_acquire를 사용하기 때문에, 저장은 읽기와 동기화(synchronizes-with)된다. x에 대한 store은 y에 대한 store 이전에 발생(happens-before)하는데, 이는 같은 스레드 존재하기 때문입니다. y는 y끼리, x는 x끼리 happens-before의 관계가 성립하기 때문에 결국 x의 읽기는 반드시 true가 되고, assert는 발생할 수 없게 됩니다.
[획득-해제 순서로 추이적 동기화 구현]
추이적 순서에 대해 생각하려면, 최소한 3개의 스레드가 필요합니다.
- 첫번째 스레드는 몇몇 공유 변수들을 변경하고 그들 중 하나에 store-release를 수행
- 두 번째 스레드는 store-release에 종속된 변수를 load-acquire를 수행하고 두 번째 공유 변수에 store-release를 수행
- 세번째 스레드는 그 두번째 공유 변수에 대해 load-acquire를 수행
load-acquire 연산이 store-release 연산에 의해 쓰여진 값을 본다면, 이 세번째 스레드는 첫번째 스레드에 의해 저장된 다른 변수들의 값을 읽을 수 있어 동기화 관계를 보장되는데, 이는 중간 스레드가 건드리지 않아도 가능해야 합니다.
Listing 5.9 Transitive synchronization using acqure and release ordering
std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);
void thread_1()
{
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141, std::memory_order_relaxed);
data[4].store(2003, std::memory_order_relaxed);
sync1.store(true, std::memory_order_release);
}
void thread_2()
{
while (!sync1.load(std::memory_order_acquire));
sync2.store(true, std::memory_order_release);
}
void thread_3()
{
while (!sync2.load(std::memory_order_acquire));
assert(data[0].load(std::memory_order_relaxed) == 42);
assert(data[1].load(std::memory_order_relaxed) == 97);
assert(data[2].load(std::memory_order_relaxed) == 17);
assert(data[3].load(std::memory_order_relaxed) == -141);
assert(data[4].load(std::memory_order_relaxed) == 2003);
}이 프로그램에서는 sync1과 sync2를 묶어 thread_1과 thread_3을 동기화 시킵니다. 이는 thread_1에서 sync1을 저장하면 sync1의 값을 기다리고 있던 thread_2에서 sync2를 저장하고, 이를 thread_3이 받아 확인합니다. 이는 확실하게 happen-before 관계가 연계된 것입니다.
또 다른 방법으로는 thread_2에서 memory_order_acq_rel를 가지는 read-modify-write 연산을 사용하여 sync1과 sync2를 하나의 변수로 줄일 수도 있습니다. 이때 thread_3에서는 2번 연산한 값에 반응하도록만 해야합니다. 또 다른 방법으로는 compare_exchange_strong()을 사용하여 값이 오직 한번만 업데이트 되도록 보장하는 것이다.
읽기-수정-쓰기 작업을 사용하는 경우 원하는 의미를 선택하는 것이 중요합니다. 이 경우 의미론 획득과 릴리스 모두를 원하므로 memory_order_acq_rel이 적절하지만 다른 순서도 사용할 수 있습니다. memory_order_acquire을 사용하는 fetch_sub 연산은 release 연산이 아니기 때문에 값을 저장하더라도 어떤 것과도 동기화되지 않고, 값을 저장하더라도 fetch_or의 읽기 부분이 acquire 연산이 아니기 때문에 memory_order_release로 동기화할 수 없습니다. memory_order_acq_rel 시맨틱을 가진 읽기-수정-쓰기 연산은 acquire과 release 둘 다로 동작하므로 동기화될 수 있습니다.
acquire_release 작업을 순차적으로 일관된 작업과 혼합하는 경우 load는 acquire처럼, store은 release처럼 순차적으로 acquire-release 작업을 일관된 순서로 작업하지만 relaxed 작업에서는 acquire-release 사용으로 인한 happens-before 관계의 동기화 한계 내에서 자유롭게 순서가 구성됩니다.
잠재적으로 직관적이지 않은 결과에도 불구하고, 잠금을 사용한 모든 사람은 동일한 순서 문제를 해결해야 했습니다: 뮤텍스를 잠그는 것은 acquire 작업이고 뮤텍스를 잠금 해제하는 것은 release 작업입니다. 뮤텍스의 경우 값을 쓸 때 잠겼던 값을 읽을 때 동일한 뮤텍스가 잠겨 있어야 하며, 여기서도 마찬가지라는 것을 알게 됩니다. 획득 및 해제 작업이 동일한 변수에 있어야 순서가 지정되며, 데이터가 뮤텍스로 보호되는 경우, 잠금의 배타적 특성은 잠금과 잠금 해제가 순차적으로 일관된 작동이었다면 어떤 결과가 나왔을지 구분할 수 없다는 것을 의미한다. 마찬가지로, 원자 변수에서 획득 및 해제 순서를 사용하여 간단한 잠금을 구축하면 잠금을 사용하는 코드의 관점에서 동작은 순차적으로 일관되게 나타납니다.
원자적 작업에 대해 순차적으로 일관된 주문의 엄격함이 필요하지 않은 경우 acquire-release 순서 조합별 동기화는 순차적으로 일관된 작업에 필요한 전범위적 순서보다 훨씬 낮은 동기화 비용을 발생시킬 수 있습니다. 이는 직관적이지 않은 작업 순서들이 올바르게 작동하고 동작이 문제가 되지 않도록 보장하는데 필요한 노오오오력입니다.
[획득-해제 순서의 데이터 의존성과 memory_order_consume]
memory_order_consume은 acquire-release 모델의 일부분이지만 특별합니다. 이는 거의 데이터 의존성에 관한 것으로, 스레드간 happends-before 관계에 데이터 의존성 의미를 추가시킨다. 하지만 C++17에서부터 쓰지말라고 했으니 넘어가겠습니다 ㅎㅎ.... 넘 좋아 ㅎㅎ...
5.3.4. Release sequences and synchronizes-with
만약 release-acquire 관계가 구축되어 체인에서의 각 연산이 이전 연산에 의해 쓰여진 값을 읽는다면, synchronizes-with 혹은 dependency-ordered-before 관계를 가집니다. 즉, 메모리 순서 테그에 의해서 동기화된 순서를 가지며 연결되고, 이러한 체인에서의 모든 읽기-변경-쓰기 연산들은 어떠한 메모리 순서라도(memory_order_relaxed 조차도) 가질 수 있게 됩니다. 이것이 무엇을 의미하고 왜 중요한지를 보기 위해, 공유 큐안의 항목의 수의 카운트로서 사용되는 atomic<int>를 살펴봅시다.
Listing 5.11 Reading values from a queue with atomic operations
std::vector<int> queue_data;
std::atomic<int> count;
void populate_queue()
{
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0; i < number_of_items; ++i) {
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release); <-- (1) 초기 저장
}
void consume_queue_items()
{
while (true) {
int item_index;
if ((item_index = count.fetch_sub(1, std::memory_order_acquire))<=0) { <--(2) RMW 연산
wait_for_more_items(); <-- (3) 더 많은 항목들을 기다린다
continue;
}
process(queue_data[item_index - 1]); <-- (4) queue_data를 읽는 것은 안전하다
}
}
int main()
{
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
}기본적으로 값을 저장한 뒤, store로 release를 하면, fetch_sub에서 acquire하여 이를 개수만큼 아이템을 소비하는 식으로 진행이 됩니다. 이는 consume_queue_items를 사용하는 스레드가 하나라면 괜찮지만, 2개가 되는 순간 fetch_sub는 store에 사용된 값이 아닌 다른 값을 보게 되어 release에 대한 규칙이 존재하지 않으면, populate와 consume 사이에는 happens-before 관계가 성립하지만 두 consume 사이에 happens-before 관계를 가지지 않아 경쟁 상태가 되어 버립니다. 이러한 경우를 방지하게 위해서 fence를 이용하여 제약을 둡니다.

5.3.5. Fences
원자적 연산 라이브러리는 펜스 집합 없이는 완성되지 않았을 것입니다. 펜스는 어떠한 데이터 변경도 없이 메모리 순서 제약을 강화하는 연산이고 일반적으로 memory_order_relaxed 순서 제약을 사용하는 원자적 연산과 함께합니다. 펜스는 전역 연산이며 펜스를 수행한 스레드는 다른 원자적 연산의 순서에 영향을 줍니다. 소스 상에서 특정 연산을 침범할 수 없어 펜스는 메모리 장벽(memory barrier)라고도 불립니다. 독립된 변수에서의 relaxed 연산들은 보통 컴파일러나 하드웨어에 의해 자유롭게 재배치될 수 있는데 펜스는 이 자유도를 제한하고 전에는 존재하지 않았던 happens-before와 synchnonizes-with 관계를 도입합니다.
Listing 5.12 Relaxed operations can be ordered with fences
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); <-- (1)
std::atomic_thread_fence(std::memory_order_release); <-- (2)
y.store(true, std::memory_order_relaxed); <-- (3)
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed)); <-- (4)
std::atomic_thread_fence(std::memory_order_acquire); <-- (5)
if (x.load(std::memory_order_relaxed)) <-- (6)
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); <-- (7)
}release 펜스는 acquire 펜스와 동기화되는데, 이는 y의 load가 store에서 저장된 값을 읽기 때문이며 이는 x의 store이 x의 load 이전에 발생함을 의미합니다. 따라서, 읽혀진 값은 true이며 assert는 유효하게 됩니다.
양쪽 펜스 모두가 필요함을 주목해야는데 synchronizes-with 관계성을 얻기 위해 한 스레드에서 release 하고 다른 스레드에서 acquire해야하는 형태를 지닙니다. 이번 같은 경우는 y에 대해 동기화를 지니게 만들어 줍니다.
만약 두 store 연산이 모두 fence 안에 존재한다면 순서를 가지지 않게 됩니다. 따라서 fence가 두 연산 사이에 올때만 순서를 강요하게 됩니다.
5.3.6. Ordering non-atomic operations with atomics
이전 예제에서 x를 보통의 비원자적 bool로 바꾸더라도, 동작은 동일함이 보장된다.
Listing 5.13 Enforcing ordering on non-atomic operations
bool x=false;
std::atomic<bool> y;
std::atomic<int> z;
void write_x_then_y()
{
x = true; <-- (1)
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed); <-- (2)
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed)); <-- (3)
std::atomic_thread_fence(std::memory_order_acquire);
if (x) <-- (4)
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); <-- (5) assert는 발동되지 않는다
} 펜스는 여전히 x의 할당과 y의 store, y의 load와 x의 load 사이의 순서를 강요하여, x의 할당과 load 사이에 happens-before 관계가 성립하도록 하여 assert는 발동되지 않습니다. 이는 x에 대한 데이터 경합이 없음을 의미하며, 한 스레드에 의해 수정되고 다른 스레드에 의해 읽혀지더라도 마찬가지입니다.
펜스만이 비원자적 작전을 지시할 수 있는 것은 아닙니다. memory_order_release/memory_order_consume이 동적으로 할당된 개체에 대한 비원자적 액세스를 정렬하는 경우에도 효과를 보았으며, 이 장의 많은 예제는 memory_order_relaxed 연산 중 일부를 일반 비원자 연산으로 대체하여 다시 작성할 수 있습니다.
5.3.7. Ordering non-atomic operations
원자적 연산을 통한 비원자적 연산의 순서는 happens-before의 순서가 매우 중요해집니다. 만약 비원자적 연산이 원자적 연산 전에 이루어지고 그 원자적 연산이 다른 스레드에서의 연산 전에 일어난다면, 비원자 연산은 다른 스레드에서의 연산보다 먼저 일어나게 됩니다. 또한 뮤텍스와 조건 변수와 같은 C++ 표준 라이브러리의 높은 수준의 동기화 기능의 기반이 됩니다.
std::memory_order_acquire는 lock() 작업에서, std::memory_order_release는 unlock()에서 flag를 통해 하나의 스레드만 통과하게 하고 구역을 나누어 이를 수행시킬 수 있도록 합니다. 이를 통해 순서가 강제된 모습을 볼 수 있게 합니다.
이전까지 설명된 각 동기화 메커니즘은 동기화 관계 측면에서 순서 보증을 제공합니다. 이를 통해 데이터를 동기화하고 주문 보증을 제공할 수 있습니다.