thread를 이용한 동시 처리에서 주요한 장점으로는 데이터를 직접 공유할 수 있다는 점이다. 따라서 이번 챕터에서는 thread 간의 안전한 데이터 공유 방법에 대해서 알아볼 것이다.
3.1. Problems with sharing data between threads
먼저 thread들 간의 공유 데이터에 대한 문제는 모두 데이터를 변경시키는 데에서 일어난다. 만약 다음과 같은 doubly linked list를 생각해보자. 이때 한 노드를 삭제한다고 하면 과정은 다음과 같이 될 것입니다.
- 삭제할 노드(N)를 선정
- N 이전 노드의 링크를 N 다음 노드로 설정
- N 다음 노드의 링크를 N 이전 노드로 설정
- 노드 삭제
와 같은 순서로 이루어지게 된다. 이때 삭제와 읽는 작업이 동시에 일어난다면 그 결과는 미정의 행동으로 이어질 것이다. 이와 같이 변하지 않아야하는 값들인 Invariant을 수정하면서 이들이 깨지는 경우 문제가 일어날 가능성이 생깁니다.
3.1.1. Race conditions
하나의 자원을 두고 2개 이상의 thread가 서로 가지려고 경쟁하는 상태를 의미합니다. 각자의 thread들은 자신에게 주어진 업무를 수행하기 위해서 일들을 수행하지만 이들은 단일적으로 수행될 때는 문제가 없지만, 동시에 수행하는 경우에는 문제가 발생할 수 있습니다. 보통 경쟁 상태라고 하는 경우는 문제가 발생할 만한 경우를 의미할 때가 많습니다. 별도의 보호 매커니즘 없이 그냥 하나의 자원을 동시에 제어하는 것을 허락 할 경우 invariants가 깨지는 현상이 발생 할 수 있습니다. 따라서 만약 병행 처리를 지원하는 프로그램을 만들 때에는 경쟁 상태를 적절하게 피하는 것이 중요하다.
3.1.2. Avoiding problematic race conditions
경쟁상태를 회피하는데에는 여러가지 방법이 존재한다.
- 자료 구조에 보호 매커니즘을 추가
- 가장 간단하다.
- 현재 수정 중인 thread에서만 중간 단계의 상태를 볼 수 있도록 한다.
- 다른 thread들은 수정 시작 전 혹은 끝난 후 상태만 볼 수 있다.
- 자료 구조 디자인과 invariant를 변경
- lock-free programming
- 메모리 모델은 5장, lock-free programming은 7장에서 소개된다.
- transaction처럼 자료구조 다루기
- 데이터 읽기 및 수정을 transaction에 저장해두었다가 한번에 수정
- software transactional memory(STM)에서 지원되며 설명은 하지 않을 예정
3.2. Protecting shared data with mutexes
한 데이터 영역에 대해서 상호 배제(mutual exclusion)하는 코드 구역을 만들 필요가 있으며, 이를 임계영역(critical section)이라 하여 한 thread가 이 영역에 진입하였을 때 다른 thread들은 진입하지 못하도록 해야한다. 이를 쉽게 구현할 수 있는 방법으로 std::mutex가 존재한다. 한 thread가 임계 영역을 사용할 때 mutex 객체에 lock을 걸고 다른 thread들이 들어오는 것을 방지하게 하고 나갈 때는 thread들이 진입을 허용하도록 mutex 객체를 unlock시킨다. mutex는 C++에서 데이터 보호를 위해 많이 쓰이지만, 알맞은 데이터를 잘 지키며, 내재된 경쟁 상태를 잘 피하고, 교착 상태(dead lock)를 회피해야하며, 너무 크거나 작은 데이터를 보호하지 않아야 한다.
3.2.1. Using mutexes in C++
C++에서 std::mutex를 생성할 때 그냥 만드는 것보다 Listing 3.1과 같이 RAII 형태의 std::lock_guard 클래스 템플릿을 활용하여 생성하는 것을 추천한다. 이는 생성할 때 lock을 걸며, 파괴될 때 unlock한다. 밑은 이를 활용한 코드이다.
Listing 3.1 Protecting a list with a mutex
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex);
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex);
return std::find(some_list.begin(), some_list.end(), value_to_find) != some_list.end();
}이 코드에서 주목해야하는 점은 전역 변수로 mutex와 보호해야하는 data를 선언하며, 수정하거나 찾을 때 lock_guard를 통해서 mutex를 활용하는 모습을 보여주고 있다.
하지만 다음과 같은 코드는 현재 잘 선호되지 않고, 객체의 private 멤버로 데이터와 mutex를 보관하며, 이를 위의 두 함수가 클래스의 멤버 함수로서 활용되어 캡슐화와 보호를 좀 더 강화할 수 있다. 하지만 이도 완벽하지 않을 수 있다. 왜냐하면 멤버 함수중 하나가 이에 대한 포인터나 참조를 리턴하게 된다면, 멤버 함수에서 mutex를 활용하여 보호를 강화시킨 것이 의미 없어진다. 즉, mutex로 구조를 짜는 것도 필요하지만 클래스 설계에서 backdoor가 없도록 보호된 데이터에 대한 접근을 막는 것도 중요하다는 것이다.
3.2.2. Structuring code for protecting shared data
우리가 위에서 본 방법인 lock_guard를 모든 곳에 사용하는 것은 상당히 어려운 일이다. 또한 위에서 말한듯 중요 데이터들의 포인터와 참조를 리턴하는 것도 중요하지만, 이 안의 데이터들의 포인터나 참조를 외부의 함수를 통해 수정되는 것도 주의해야한다.
Listing 3.2 Accidentally passing out a reference to protected data
class some_data
{
int a;
std::string b;
public:
void do_something();
};
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template<typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex> l(m);
func(data); // Pass "protected" data to user-supplied function
}
};
some_data* unprotected;
void malicious_function(some_data& protected_data)
{
unprotected=&protected_data;
}
data_wrapper x;
void foo()
{
x.process_data(malicious_function); // Pass in a malicious function
unprotected->do_something(); //Unprotected access to protected data
}위의 예제에서 process_data를 이용한다면 문제 없이 데이터를 보호할 수 있을 것 같지만, malicious_function을 이용하여 내부의 데이터가 외부로 유출되는 사태가 발생하고 만다. 즉 단순히 라이브러리르 통해서 완벽하게 보호하는 것은 불가능하고, 코드를 잘 작성하여 이를 보호하도록 만들어야한다. 따라서 다음과 같은 가이드를 따라야만 한다.
함수로부터 반환되거나, 보이는 메모리 외부에 저장하거나, 사용자 지정 함수의 인자에 넘기는 것 등 lock의 범위 밖에 있는 보호되는 데이터의 pointer와 reference를 사용하지 말 것입니다.
3.2.3. Spotting race conditions inherent in interfaces
위에서 예시를 들었던 doubly linked list를 생각해보자. 이 경우에 안전하게 데이터를 지우기 위해서 각 노드의 pointer에 대한 접근에 대한 보호를 수행했다면, 이는 지속적으로 race condition이 발생시키기에 없느니만 못하다. 즉, 개별적인 코드 보다 전체적인 흐름을 볼 줄 알아야만한다. Listing 3.3과 같이 std::stack 컨테이너를 활용한 경우를 보자.
Listing 3.3 The interface to the std::stack container adapter
template<typename T, typename Container=std::deque<T> >
class stack
{
public:
explicit stack(const Container&);
explicit stack(Container&& = Container());
template <class Alloc> explicit stack(const Alloc&);
template <class Alloc> stack(const Container&, const Alloc&);
template <class Alloc> stack(Container&&, const Alloc&);
template <class Alloc> stack(stack&&, const Alloc&);
bool empty() const;
size_t size() const;
T& top();
T const& top() const;
void push(T const&);
void push(T&&);
void pop();
void swap(stack&&);
template <class... Args> void emplace(Args&&... args);
};생성자와 swap 함수는 제외한 std::stack의 멤버함수 5가지를 보자.
- push() : 새로운 요소를 스택에 추가
- pop() : 맨 위의 요소를 스택에서 제거
- top() : 맨 위의 요소를 읽음
- empty() : 스택이 비었는지 확인
- size() : 요소의 갯수를 파악
생성자와 swap 함수는 제외한 std::stack의 멤버함수 5가지를 보자. 위의 코드에서는, 내부를 아무리 mutex를 이용하여 보호를 잘 해도, multithreading 코드에서는 경쟁 상태가 발생할 수 밖에 없습니다. 이는 mutex에 기반한 구현의 문제가 아닌 인터페이스의 문제이다. 만약 다음과 같은 코드가 실행된다고 생각해보자
stack<int> s;
if (!s.empty())
{
int const value = s.top();
s.pop();
do_something(value);
}값을 보는 함수는 top() 이고 값을 지우는 함수는 pop() 이기 때문에 그 사이에 뭔가 일이 발생한다면 원치 않는 결과가 발생 할 수 있습니다. 위 경우 thread A, B 모두 같은 값은 top 값을 가지게 되며, stack에는 읽히지도 않은 2번째 값도 같이 삭제가 됩니다. 혹은 컨테이너가 복사되는 도중에 원소 값이 바뀐다던지, 인자로 넘길 때 다른 값을 주게 되는 경우 등 다양한 미정의 행동을 유도하게 됩니다. 이러한 문제를 해결하기 위해서는 인터페이스의 변경이 필요한데, 이는 여러가지 방법이 존재합니다.
Option 1: pop()의 인자로 들어온 값에 reference를 넘기기
std::vector<int> result;
some_stack.pop(result);보통 잘 작동하지만 받아줄 컨테이너를 미리 만들어두어야 하기에 비용이 비싸다기도 하며, 타입에 따라 default가 없는 경우 생성이 불가능한 경우도 존재합니다. 그리고 할당이 불가능한 경우 (이동 연산 혹은 이동 생성만 지원하는 경우)에는 생성이 불가능합니다.
Opiton 2: copy 생성자와 move 생성자의 예외가 없도록 구현
많은 타입은 예외 처리를 하지 않는 복사 생성자를 가지고 있는데, C++11에서는 복사 생성자가 예외 처리를 하더라도 예외 처리를 하지 않는 이동 생성자를 가집니다. 따라서 예외 처리 없이 값에 의해 안전한 경우에만 thread-safe 스택에서의 사용을 허가시킵니다.
Option 3: pop()이 된 item의 포인터를 리턴
값을 주는 것보다는 포인터로 주는 것이 포인터 복사에 문제가 없기 때문에 예외 처리를 생각하지 않고 편하게 할 수는 있습니다. 하지만, 메모리에 직접적으로 영향을 주는 포인터를 반환하여 관리가 힘들어지고, int와 같이 간단한 경우는 불필요하게 오버헤드를 발생시킵니다. 따라서 std::shard_ptr를 사용하는 것이 좋겠습니다.
Option 4: 1번과 2,3 중 하나를 선택해서 같이 적용
제너릭 코드에서는 특히 유연성이 전혀 규정되어있지 않아야만 합니다. 만약 옵션 2나 3을 선택했으면, 상대적으로 옵션 1을 제공하는 것 보다 쉽고, 이는 코드 사용자에게 가장 적은 비용을 들이면서 가장 적절한 어떤 옵션을 선택할 것인지를 제공합니다.
위의 방법 중 옵션 1과 3을 구현한 예시로 Lisiting 3.5에서는 인터페이스에서 race condition이 없도록 구현한 스택 클래스 정의를 보여주고 있습니다.
Listing 3.5 A fleshed-out class definition for a thread-safe stack
#include <exception>
#include <memory>
#include <mutex>
#include <stack>
struct empty_stack: std::exception
{
const char* what() const throw();
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack(){}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data=other.data; // Copy performed in consturctor body
}
threadsafe_stack& opterator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard(std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop() // option 1의 구현
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack(); // Check for empty before trying to pop value
//Allocate return value before modifying stack
std::shared_ptr<T> const res(std::make_shared<T>(data.top()));
data.pop();
return res;
}
void pop(T& value) // option 1의 구현
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
value=data.pop();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};먼저 복사할 때를 보면, 복사할 객체의 mutex에 락을 걸고 복사를 수행하여 안전하게 수행되는 것을 확인할 수 있다. 또한, 모든 경우에 하나의 mutex를 활용하여 lock을 거는 것을 볼 수가 있는데 이는 안전할 지는 몰라도 너무 작은 단위에도 lock을 걸어, 멀티쓰레딩의 장점을 전혀 살리지 못하고 있다. 좀 더 좋은 결과를 내기 위해서는 여러 개의 mutex를 활용하여 데이터를 보호할 필요가 있으며, mutex로 보호되는 범위를 넓히는 것도 주요하다. 하지만 이 경우에는 이를 수행하기 어려운데, mutex들이 각 객체를 보호하고 있고, 이의 상위는 사용자 혹은 해당 클래스가 하나의 mutex만을 가지도록 해야하기 떄문이다. 또한, 2개 이상의 mutex를 사용한다면 deadlock이라 하는 다른 문제에 맞부딪히게 된다.
3.2.4. Deadlock: the problem and a solution
2개 이상의 thread들이 다른 thread가 선점하고 있는 자원을 사용하기 위해 무기한 대기하게 되는 현상을 교착상태(deadlock)이라 한다. 예를 thread T1, T2기 자원 A, B에 대해 경쟁조건을 피하기 위해 lock을 걸고 사용할 경우,
- thread T1이 A라는 자원에 lock을 걸었고, thread T2가 B라는 자원에 lock을 걸었다고 하자.
- thread T1이 B 자원을 사용하기 위해, thread T2 역시 A 자원을 사용하기 위해 접근할 때, 양 쪽 모두 이미 누군가가 사용 중이어서 wait 상태가 된다.
- T1, T2는 영원히 자기가 가진 자원에 대한 lock을 해제하지 못하고 이를 교착 상태라고 한다.
이는 서로 자원에 lock을 거는 순서가 달라 생기는 현상인데, 이를 없애주기 위해서는 모든 thread들이 자원에 lock을 일정한 순서로 걸도록 만들면 된다. 고맙게도 C++ 표준 라이브러리는 std::lock을 지원하여, 2개 이상의 mutex에 lock을 걸 수 있어, 교착 상태를 피할 수 있다. 다음은 이를 사용한 예시이다.
Listing 3.6 Using std::lock() and std::lock_guard in a swap operation
class some_big_object;
void swap(some_big_object& lhs, some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if (&lhs==&rhs)
return;
std::lock(lhs.m, rhs.m); // (1)
std::lock_guard<std::mutex> lock_a(lhs.m, std::adopt_lock); // (2)
std::lock_guard<std::mutex> lock_b(rhs.m, std::adopt_lock); // (3)
swap(lhs.some_detail, rhs.some_detail);
}
};- (1) : 2개의 mutex에 동시에 lock을 걸었습니다.
- (2),(3) : 이미 걸린 lock을 RAII형태로 관리하도록 lock_adopt 인자를 보내 이미 lock 걸려있다는 것을 인지시킨 채로 std::lock_guard로 생성하였습니다.
C++17에서는 위의 코드를 처음부터 RAII 형태로 보관할 수 있도록 하는 std::scoped_lock<>을 제공합니다. 이는 생성될 때 std::lock과 같은 역할을 하며, 소멸할 때 이를 해제합니다. 다음과 같이 쓰일 수 있습니다.
void swap(X& lhs, X& rhs)
{
if (&lhs==&rhs)
return;
std::scoped_lock guard(lhs.m, rhs.m);
swap(lhs.some_detail, rhs.some_detail);
};3.2.5. Further guidelines for avoiding deadlock
교착상태는 lock에서 자주 일어나지만 lock에 한정되어 있지는 않습니다. 2개의 thread가 서로를 join()으로 기다리게 하면 바로 교착상태를 만들 수 있습니다. 따라서 이런 경우를 해결할 전체적인 가이드라인이 필요합니다.
- Avoid nested locks - 이미 한 thread가 lock을 얻었다면, 다른 thread에서 lock을 얻지 못하도록 합니다. 각 thread들이 단일 lock만을 사용하기에 교착 상태가 일어날 수가 없게 됩니다.
- Avoid calling user-supplied code while holding a lock - 사용자가 작성한 코드가 어떠한 일을 할지 모르기 때문에, 사용하지 않는 것이 좋다.
- Acquire locks in a fixed order - 원형 리스트 같은 경우 혹은 swap 같이 들어오는 순서에 맞춰 lock을 걸어주는 경우에 순환 대기에 걸리는 경우가 존재한다.
- Use a lock hierarchy - mutex들 간의 계층을 구성하여 밑의 계층의 mutex에 lock이 걸려있다면, 상위 계층에는 lock을 걸 수 없도록 하는 방법이다. C++ Library 에서 직접적으로 지원을 하지 않기에, Listing 3.7과 같이 구현할 수 있다.
Listing 3.7 Using a lock hierarchy to prevent deadlock
hierarchical_mutex high_level_mutex(10000); // (1)
hierarchical_mutex low_level_mutex(50000); // (2)
int do_low-level_stuff();
int low_level_func()
{
std::lock_guard<hierarchical_mutex> lk(low_level_mutex); // (3)
return do_low_level_stuff();
}
void high_level_stuff(int some_param);
void high_level_func()
{
std::lock_guard<hirearchical_mutex> lk(high_level_mutex); // (4)
high_level_stuff(low_level_func()); // (5)
}
void thread_a() // (6)
{
high_level_func();
}
hierarchical_mutex other_mutex(6000); // (7)
void do_other_stuff();
void other_stuff()
{
high_level_func(); // (8)
do_other_stuff();
}
void thread_b() // (9)
{
std::lock_guard<hierarchical_mutex> lk(other_mutex); // (10)
other_stuff();
}-
(6) : thread_a()가 high_level_func()를 호출합니다.
- (4) : high_level_mutex(10000)로 만들어진 mutex에 lock을 걸고 low_level_func() 작업을 합니다.
- (3) : low_level_mutex(50000)로 만들어진 mutex에 lock을 시도하므로 해당 작업은 성공합니다.
- (4) : high_level_mutex(10000)로 만들어진 mutex에 lock을 걸고 low_level_func() 작업을 합니다.
-
(9) : thread_b()가 other_mutex(6000)에 lock을 걸고 other_stuff()을 호출합니다.
- (8) : high_level_func()을 호출합니다.
- (4) : high_level_mutex(10000)로 만들어진 mutex에 lock을 시도하므로 실패합니다. 만약 low_level_mutex라면 더 작은 값을 갖기에 호출 가능했을 것입니다.
- (8) : high_level_func()을 호출합니다.
이와 같이 하위에서 상위로 갈 때 해당 mutex에 lock을 걸 수 없도록 만듭니다. 이렇게 mutex가 스스로 서로의 lock 순서를 강요하기 때문에 계층구조의 mutex 사이에서의 교착상태가 일어나지 않습니다. hierarchical_mutex는 표준이 아니지만 작성하기 쉽습니다. listing 3.8에서 단순한 구현을 보여줍니다.
Listing 3.8 A simple hierarchical mutex
class hierarchical_mutex
{
std::mutex internal_mutex;
unsigned long const hierarchy_value;
unsigned long previous_hierarchy_value;
static thread_local unsigned long this_thread_hierarchy_value; // (1)
void check_for_hierarchy_violation()
{
if(this_thread_hierarchy_value <= hierarchy_value) // (2)
{
throw std::logic_error("mutex hierarchy violated");
}
}
void update_hierarchy_value()
{
previous_hierarchy_value=this_thread_hierarchy_value; // (3)
this_thread_hiearchy_value=hierarchy_value;
}
public:
explicit hierarchical_mutex(unsigned long value);
hierarchy_value(value),
previous_hierarchy_value(0)
{}
void lock()
{
check_for_hierarchy_violation();
internal_mutex.lock(); // (4)
update_hierarchy_value(); // (5)
}
void unlock()
{
if(this_thread_hierarchy_value != hierarchy_value) // (2)
{
throw std::logic_error("mutex hierarchy violated"); // (9)
}
this_thread_hierarchy_value=previous_hierarchy_value; // (6)
internal_mutex.unlock();
}
bool try_lock()
{
check_for_hierarchy_violation();
if(!internal_mutex.try_lock()) // (7)
return false;
update_hierarchy_value();
return true;
}
};
thread_local unsigned long
hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX); // (8)(1) : this_thread_hierarchy_value를 thread_local로 수정합니다.
(8) : 이때 이 값은 ULONG_MAX로 초기화 되어 처음에는 어떤 mutex도 lock이 가능하도록 설정합니다. 따라서 처음 lock()을 호출하면 무조건 통과하게 됩니다.
(2) : this_thread_hierarchy_value 보다 작은 값에 대해서만 통과시키며, 아닐 경우 예외를 발생합니다.
(4) : internal_mutex.lock()를 실행해서 lock을 겁니다.
(5) : this_thread_hierarchy_value의 값을 자신의 값으로 update 하기 위하여 (3)으로 가 이전의 this_thread_hierarchy_value를 previous_hierarchy_value로 저장하는 부분입니다. 이후 this_thread_hierarchy_value보다 큰 값에 대해서는 lock()을 걸수가 없게 되며, this_thread_hierarchy_value보다 작은 값에 대해서는 lock()을 걸고 해당 값으로 this_thread_hierarchy_value를 update합니다.
unlock()을 하는 부분을 보면 먼저 previous_hierarchy_value값으로 this_thread_hierarchy_value를 update 합니다. 이제 자신은 unlock 되었으니 자신보다 바로 앞의 값으로 변경해줘서 해당 값보다 낮은 lock을 걸수 있게 설정해 줍니다. 그런 뒤 자신의 internal_mutex 를 unlock() 합니다.
try_lock()은 만약 internal_mutex-(7)에서 try_lock() 호출이 실패한다면, lock을 소유하지 않고, 그래서 계층값을 갱신하지 못하며, true대신 false를 반환한다는 것을 제외하고는 lock()과 똑같습니다.
- Extending these guidlines beyond locks
교착상태는 단지 lock에 의해서만 발생하는 것이 아닌 thread 자체에서도 발생이 가능하기에 thread가 lock을 잡고 있는데, 해당 thread를 join() 하는 것은 교착상태를 발생 시킬 수 있습니다. 그러므로 thread 또한 hierarchy_value를 두어서 위와 같이 관리하는 것도 생각해 볼 수 있습니다. 위에서 본 것과 같이 교착상태를 피하는 코드를 std::lock() ,std::lock_guard를 이용해서 단순한 lock의 경우를 살펴보았습니다만, 때때로는 이것으로 해결이 안되는 경우도 있습니다. 그러한 경우에는 std::unique_lock를 이용하여 좀 더 유연하게 사용을 해야 합니다.
3.2.6. Flexible locking with std::unique_lock
std::unique_lock은 invariants 를 완화시켜 std::lock_guard 보다 조금 더 flexibility 한 기능을 제공합니다. std::unique_lock 객체는 mutex 를 항상 소유하고 있지는 않습니다. 객체 생성자의 두번째 인자에 따라 다른 행동을 취합니다.
- std::adopt_lock : mutex를 lock 상태로 생성합니다.
- std::defer_lock : mutex를 unlocked 상태로 생성합니다. 이후 lock을 걸려면 std::unique_lock 객체의 .lock() 을 호출, 또는 std::lock()에 std::unique_lock 객체를 인자로 전달해야 합니다. (mutex객체가 아닌 std::unique_lock 객체임을 주의해야 합니다.)
이를 활용한 코드는 Listing 3.9와 같습니다.
Listing 3.9 Using std::lock() and std::unique_lock in a swap operation
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs == &rhs)
return;
std::unique_lock<std::mutex> lock_a(lhs.m,std::defer_lock); /* (1) */
std::unique_lock<std::mutex> lock_b(rhs.m,std::defer_lock); /* (1) */
std::lock(lock_a,lock_b); /* (2) */
swap(lhs.some_detail,rhs.some_detail);
}
};이 예제는 앞서 Listing 3.6에서 본 것과 비슷한 예시인데, defer_lock으로 만들어준 후에 lock을 통해 동시에 소유권을 이전했습니다. std::lock()의 인자로 사용 될수 있습니다. (1의 멤버 함수가 지원되기 때문이죠.) mutex의 소유권 정보를 저장하고 있는 flag를 가지고 있습니다. (그래서 이만큼의 공간이 더 필요하고, 관련 연산으로std::lock_guard보다 좀 더 느리고 큰 공간을 차지합니다.)
3.2.7. Transferring mutex ownership between scopes
std::unique_lock 객체는 자체 mutex를 가지지 않기에, 복사는 불가능하고 mutex 의 소유권을 인스턴스 사이에 이동을 통해 전달 가능합니다. 이는 값이 lvalue인 경우는 std::move 함수와 같이 명시적으로 수행되어야하며, rvalue인 경우는 자동적으로 수행됩니다.
std::unique_lock 은 함수가 mutex 에 대한 lock 과 호출자에 대한 lock 의 소유권 이전을 허용하여, 호출자는 동일한 lock 상태에서 작업이 가능해집니다. 아래의 코드는 이러한 예제 중 하나입니다. get_lock() 함수는 mutex 의 lock 을 획득 하고 호출자에게 lock 을 반환하기 전에 prepare_date() 를 수행합니다.
std::unique_lock<std::mutex> get_lock()
{
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk; /* (1) */
}
void process_data()
{
std::unique_lock<std::mutex> lk(get_lock()); /* (1) */
do_something();
}process_data() 함수내에서 다른 곳에서 전달 받은 lock을 이용해서 작업을 수행하는 간단한 코드 입니다. 위 과정을 객체화한 gateway class로 생성하여 이용하면 됩니다. 데이터로의 모든 접근은 이 gateway class 를 통해서 get_lock() 같은 함수로 객체를 획득해서 수행하는 방법입니다.
3.2.8. Locking at an appropriate granularity
lock을 잘게 쪼갤수록 병렬성은 올라가지만, 실제로 보호되어야할 데이터 전체 범위 이하로 쪼개면 일관성이 깨질수 있습니다. lock을 크게 잡을수록 데이터 보호는 보장하지만, 병렬성이 떨어집니다. 누가봐도 오랜시간이 걸리는 작업 (예를 들어서 File I/O 같은 경우)에는 lock을 획득한 상태에서 하지 말아야 합니다. std::unique_lock이 이런 상황에서 좋습니다.
void get_and_process_data()
{
std::unique_lock<std::mutex> my_lock(the_mutex);
some_class data_to_process = get_next_data_chunk();
my_lock.unlock(); /* (1) */
result_type result = process(data_to_process);
my_lock.lock(); /* (2) */
write_result(data_to_process,result);
}process를 실행할 때에는 lock이 필요없기 때문에, 잠시 unlock을 해준 후 다시 lock을 걸어주는 형태를 취합니다. 이와 같이 lock을 거는 것은 데이터의 크기의 문제가 아닌 lock이 걸린 동안 수행하는 작업이 얼마나 걸리는 지가 중요합니다. 이때는 다른 lock을 걸거나, lock을 건 동안에는 시간이 오래 걸리는 작업을 수행하지 말아야합니다.
Listing 3.6 과 3.9 의 교환 연산은 두개의 mutex 의 locking 을 필요로 합니다. 하지만 int 복사의 값이 싸기 때문에, 아래의 Listing 3.10에서는 한번에 1개의 mutex만 lock을 걸어 값을 각각 복사를 해온 뒤에 비교연산을 수행시켰습니다.
Listing 3.10 Locking one mutex at a time in a comparison operator
class Y
{
private:
int some_detail;
mutable std::mutex m;
int get_detail() const
{
std::lock_guard<std::mutex> lock_a(m); /* (1) */
return some_detail;
}
public:
Y(int sd) : some_detail(sd) {}
friend bool operator==(Y const& lhs, Y const& rhs)
{
if(&lhs==&rhs)
return true;
int const lhs_value = lhs.get_detail(); /* (2) */
int const rhs_value = rhs.get_detail(); /* (3) */
return lhs_value == rhs_value; /* (4) */
}
};(2)와 (3)에서 (1)의 코드로 lock을 걸면서 값을 가져오고 이를 (4)에서 비교연산 하고 있습니다. 결론적으로 잘못된 결과를 초래할 수 있습니다. 이는 각각의 값을 들고 오는 동안 바뀔 수가 있기 때문에 lhs 와 rhs가 한 순간도 같은 적이 없었음에도 같다고 판단할 수도 있습니다. 이와 같이 코드를 바꿀 때에는 의미론적으로 판단을 해야하며, race condition을 너무 의식하려다가 전체적인 흐름을 바꾸어 문제를 발생시킬 수 있습니다. 이런 경우는 std::mutex말고 다른 방식이 더 좋을 수 있습니다.
3.3. Alternative facilities for protecting shared data
mutex는 가장 일반적인 데이터 보호 방식이지만 유일한 방법은 아닙니다. 특정 작업(일반적으로 초기화 나 데이터 갱신)에서는 하나의 thread에서만 접근해야 하지만, 읽기 같은 작업은 동시에 해도 문제가 없는 데이터가 있는 경우가 많습니다. 이는 효율성을 떨어뜨리기에, C++ Standard에서는 초기화 시 데이터 보호를 위한 방법을 제공하고 있습니다.
3.3.1. Protecting shared data during initialization
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); /* (1) */
}
resource_ptr->do_something();
}비용이 비싼 공유 데이터이기에 요청되는 때에 만들어서 작업을 수행하는 코드(lazy initialization)를 만들었고, 나머지 부분은 multithreading에 안전하다고 가정해봅시다. 이 코드에서 위험한 부분은 초기화가 되었는지 파악하고 이를 만드는 부분인데, 하지만 아무런 보호장치가 없으므로 싱글 스레드 환경이 아닌 경우에는 동시에 초기화가 일어 날 수 있습니다. 만약 mutex를 활용한다면 다음과 같이 됩니다.
Listing 3.11 Thread-safe lazy initialization using a mutex
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex);
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);
}
lk.unlock();
resource_ptr->do_something();
}
void foo1()
{
if(!resource_ptr)
{
std::unique_lock<std::mutex> lk(resource_mutex);
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);
}
lk.unlock();
}
resource_ptr->do_something();
}
이 코드는 평범하지만, foo 함수를 수행할 때, mutex에 인해 초기화 여부 확인 작업이 직렬화되면서 능률이 떨어지게 됩니다. 따라서 double-checked locking 패턴을 활용하여 만든 foo1 함수 같은 경우는 초기화되지 않은 경우에만 진입하여, mutex를 통해 초기화를 직렬화 시키고, 한번더 이를 체크하는 것으로 중복 초기화를 방지하였습니다. 하지만 이 패턴 또한 내재된 경쟁 상태 가능성을 가지고 있습니다.
참조 : https://m.blog.naver.com/jjoommnn/130036635345
Double-Checked Locking Pattern(이하 DCLP)는 두가지 내재된 문제점을 가지고 있습니다.
[CPU 아키텍쳐 문제]
CPU가 어디서 변수 값을 읽느냐에 따라 lock 밖에서 읽는 것과 lock 안에서 읽는 것이 동기화되지 않을 수 있습니다.
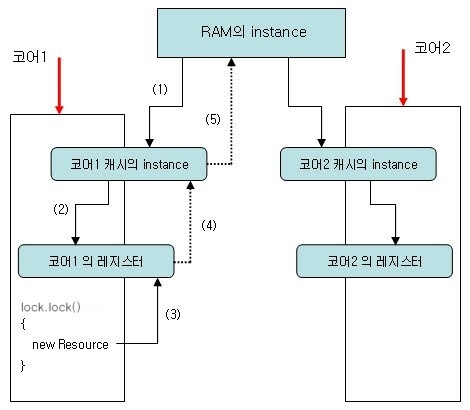
일반적으로는 우리는 CPU가 RAM에서 값을 가져온다고 생각하지만 각 코어에서 사용하는 cache 및 레지스터에서의 값이 램과 같지 않아 일관성 문제(coherency problem)이 발생할 수 있습니다. 위와 같은 것을 생각할 때 코어 1에서 resource_ptr을 위해 new some_resource를 통해 초기화를 시도합니다. 하지만 이때 (3)을 통해서 처음 수행하고 (4), (5)까지 연결이 되어야하는데, lock 블록을 벗어난 뒤에 일어날 수도 있고, 아예 이루어지지 않는 경우도 존재합니다. 따라서 코어 2에서는 이 값을 읽지 못하고 다시 한번 더 초기화하는 문제가 발생할 수도 있습니다.
[재배치 문제]
위의 코드에서 new some_resource를 수행할 때 일반적인 new의 수행은
- 객체를 위한 메모리 할당
- 객체의 생성자 할당
- 객체의 레퍼런스를 변수에 저장
의 순서로 일어나게 됩니다. 하지만 컴파일러의 최적화에 따라 위의 2, 3 순서가 바뀌어
- 객체를 위한 메모리 할당
- 객체의 레퍼런스를 변수에 저장
- 객체의 생성자 할당
의 순서로 일어나, 변수에 미리 값이 저장되었지만 초기화가 제대로 일어나지 않은 경우가 발생합니다. 이에 lock 밖의 값이 값은 가지지만 초기화되지 않은 채로 do_something을 수행하여 문제가 발생할 수도 있습니다.
좀 더 자세한 것은 챕터 5에서 자세히 다루게 됩니다. 이에 따라 C++ 표준 협회는 std::once_flag와 std::call_once를 제공하여 이 문제를 해결합니다. 위의 코드 처럼 mutex를 lock하고 포인터를 확인하기 보다는 std::call_once을 통해 안전하고 비교적 싼 비용으로 초기화를 수행할 수 있습니다.
다음의 예는 Listing 3.11을 std::call_once를 이용하여 재구성 하였습니다.
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; /* (1) */
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag, init_resource);
resource_ptr->do_something();
}Listing 3.12 Thread-safe lazy initialization of a class member using std::call_once
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection=connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_):
connection_details(connection_details_)
{}
void send_data(data_packet const& data) /* (1) */
{
std::call_once(connection_init_flag,&X::open_connection,this); /* (2) */
connection.send_data(data);
}
data_packet receive_data() /* (3) */
{
std::call_once(connection_init_flag,&X::open_connection,this); /* (2) */
return connection.receive_data();
}
};초기화는 (1)이나 (3) 함수의 첫 호출 때 이루어 집니다. 이 떄 데이터 초기화를 위한 멤버 함수 open_connection()는 std::call_once에 포인터로 전달되어야 합니다. (2)에 std::bind처럼 함수포인터의 자기 자신을 전달하여 사용 할 수 있습니다. std::once_flag는 복사 및 이동을 둘다 지원하지 않습니다.
또 다른 경쟁 상태를 유발할 수 있는 것은 static으로 선언된 지역 변수입니다. 이는 여러 thread에서 호출 가능하기 때문에 C++11 이전에는 문제가 많았지만 C++11에 들어서면서 초기화가 한 thread에서만 일어나도록 설정되어 해결되었습니다. 따라서 std::call_once가 필요한 전역 객체에 대한 대안으로 쓰일 수 있습니다.
class my_class;
my_class& get_my_class_instance()
{
static my_class instance; (1)
return instance;
}위와 같은 코드는 초기화된 후에 변경되지 않는 데이터 구조를 상정하고 있었지만, 데이터의 값이 변경되는 경우는 별도의 보호 매커니즘을 필요로 합니다.
가끔 데이터를 변경하는 데이터 구조가 존재한다면, 데이터가 변경하는 동안은 접근을 배제하도록 만들어야한다. 이에 std::mutex를 사용하는 것은 데이터 구조를 병렬적으로 읽는 것을 방지하기에 너무 좋지 않다. 이를 해결하기 위한 mutex를 reader-writer mutex 형태라고 하며, 이는 배타적인 접근을 하는 하나의 thread를 허용하는 "writer" 작업과 여러 개의 thread들의 동시적인 접근을 허용하는 "reader" 작업으로 두개의 다른 종류의 사용법이 존재하기 떄문이다. C++17에서는 std::shared_mutex와 std::shared_timed_mutex로 두가지를 제공하며, C++14에서는 std::shared_time_mutex를, C++11에서는 하나도 존재하지 않는다.
std::shared_mutex와 std::shared_timed_mutex의 차이점은 std::shared_timed_mutex는 4.3에서 더 설명하겠지만 추가적인 작업을 수행할 수 있는 반면에, std::shared_mutex는 추가적인 작업을 필요로 하지 않는다면 성능상 이점을 볼 수도 있다. 따라서 std::mutex를 사용하기 보다는 std::shared_mutex를 사용하면 좋고, shared_lock<std::shared_mutex>를 통해 공유 데이터를 읽고 있는 thread들에 대해 shared access를 획득할 수 있습니다.
결국, 배타적인 lock을 획득하고자 하는 다른 한 thread가 존재한다면 shared lock을 가진 thread들의 lock을 없앨 때까지 막히게 되고, 배타적인 lock을 가지고 있는 thread가 있다면 다른 thread들이 shared lock이나 배타적인 lock을 획득하지 못한다는 점입니다.
Listing 3.13 Protecting a data structure with std::shared_mutex
#include <map>
#include <string>
#include <mutex>
#include <shared_mutex>
class dns_entry;
class dns_cache
{
std::map<std::string,dns_entry> entries;
mutable std::shared_mutex entry_mutex;
public:
dns_entry find_entry(std::string const& domain) const
{
std::shared_lock<boost::shared_mutex> lk(entry_mutex); /* (1) */
std::map<std::string,dns_entry>::const_iterator const it= entries.find(domain);
return (it==entries.end())?dns_entry():it->second;
}
void update_or_add_entry(std::string const& domain, dns_entry const& dns_details)
{
std::lock_guard<std::shared_mutex> lk(entry_mutex); /* (2) */
entries[domain]=dns_details;
}
};find_entry()는 std::shraed_lock<std::shared_mutex>을 이용하여 read-only 접근을 허용하며, 다른 스레드들도 동시에 find_entry()로 접근이 가능합니다. update_or_add_entry()는 std::lock_guard<>를 사용하므로 다른 쓰레드의 접근을 막습니다. 해당 작업동안 find_entry()의 호출까지 모두를 블록합니다.
3.3.3. Recursive locking
std::mutex로 한 thread가 이미 소유한 mutex를 lock하려고 한다면 미정의 행동이 발생합니다. 하지만 상황에 따라서 한 thread가 먼전 잠근 mutex를 unlock하기 전에 획득해야하는 경우가 존재합니다. 이를 위해 C++ 표준 라이브러리에서 std::recursive_mutex를 제공하여 이를 사용합니다. 대신 이를 사용하는 경우에는 전체적인 코딩 디자인을 조금 바꿔야할 필요성이 생깁니다.
'C++공부 > Concurrency in Action' 카테고리의 다른 글
| 7. Designing lock-free concurrent data structures (0) | 2022.07.18 |
|---|---|
| 6. Designing lock-based concurrent data structures (0) | 2022.07.17 |
| 5. The C++ memory model and operations on atomic types (0) | 2022.07.17 |
| 4. Synchronizing concurrent operations (0) | 2022.07.15 |
| 2. Managing threads (0) | 2022.05.13 |