역사적으로 그래픽 가속화는 삼각형 내의 픽셀에 대해 보간을 통해 값을 구하고, 표면에 이미지를 입히면서 시작하였습니다. 이러한 계산이 속도에 영향을 미치기에 이에 병렬화로 계산에 특화된 하드웨어를 만들어 그 결과가 GPU 입니다. 시간에 지남에 따라 유연성과 프로그래밍될 수 있게 되었습니다.
3.1. Data-Parallel Architectures
정지(stall)를 피하기 위해서 다양한 프로세서 구조가 사용되었습니다. CPU는 다양한 데이터 구조와 코드를 조작하기 위해 최적화 되었습니다. 이를 위해, 로컬 캐시로 CPU가 구성되어 있고, 다양한 기법을 이용하여 cache miss를 피하고자 합니다.
하지만 GPU에서는 다른 방법을 사용합니다. GPU는 shader core라 불리는 다수의 프로세서로 비슷한 데이터에 대해 한번에 작업을 수행합니다. 이들은 픽셀과 같이 인접하지만 공유 메모리 없이 독립적으로 수행될 수 있기에 가능한 작업입니다. 그렇지 않다면 다른 작업을 기다리는 상황이 발생할 수 있기 때문입니다.
GPU는 처리량에 최적화되어 있는데, 빠른 작업은 많은 자원을 소모합니다. 한정된 캐시 메모리와 제어 로직으로 각각의 shader core는 CPU 프로세서가 만나는 것보다 지연이 큽니다. 따라서 로컬 레지스터에 대해서 조금의 저장 공간을 할당하고, 텍스쳐를 가져오는 것과 같은 작업을 수행하고 기다릴 떄는, 빠르게 그 다음 작업으로 전환하여 수행할 수 있도록 합니다. 즉, 한 프로세서에서 많은 작업을 맡아, 한 작업에서 오래 기다려야하는 부분이 있다면, 이를 기다리지 않고 빠르게 다음 작업으로 넘어가 지연 시간 동안 다른 작업을 수행하여 지연 시간이 실제적으로는 없는 것과 동일하게 수행하도록 합니다. 작업 전환이 자주 일어나 지연이 조금 일어날 수 있지만, 이는 SIMD에 의해 같은 작업을 인접한 데이터에 대해서 수행할 수 있으므로, 데이터를 수행하고 전환할 때의 오버헤드가 적습니다.
GPU에서의 스레드는 입력값을 포함한 작은 메모리로 구성된 하나의 작업을 의미하며, 이들이 모여 warps 혹은 wavefront를 구성하게 됩니다. 이들은 GPU shader core에서 작업을 수행하게 되는데, 이들은 SIMD 혹은 SIMT에 의해 작업이 수행됩니다.
shader 프로그램의 자료 구조는 효율성에 영향을 줍니다. 각 스레드가 필요로 하는 메모리가 커질 수록 GPU에 할당되는 warp수가 줄어듭니다. warp의 수가 적다는 것은 swapping으로 수행되는 작업의 수가 적다는 것이고, 정지 상태에 걸릴 수도 있게 됩니다. 사용 가능한 warp를 occupancy라고 하는데, occpancy가 높다는 것은 사용 가능한 warp가 많아 좋은 퍼포먼스를 낼 수 있다는 뜻입니다. 메모리 패치의 빈번도는 지연이 얼만큼 숨겨지는 지에 영향을 줍니다.
if문과 루프를 통한 동적인 분기점도 효율성에 영향을 주는데, if문을 만나면 모든 스레드들이 평가되고 같은 작업을 해야하기에 같은 분기점에 모여야 하여 때문에 효율이 떨어집니다.
3.2. GPU Pipeline Overview
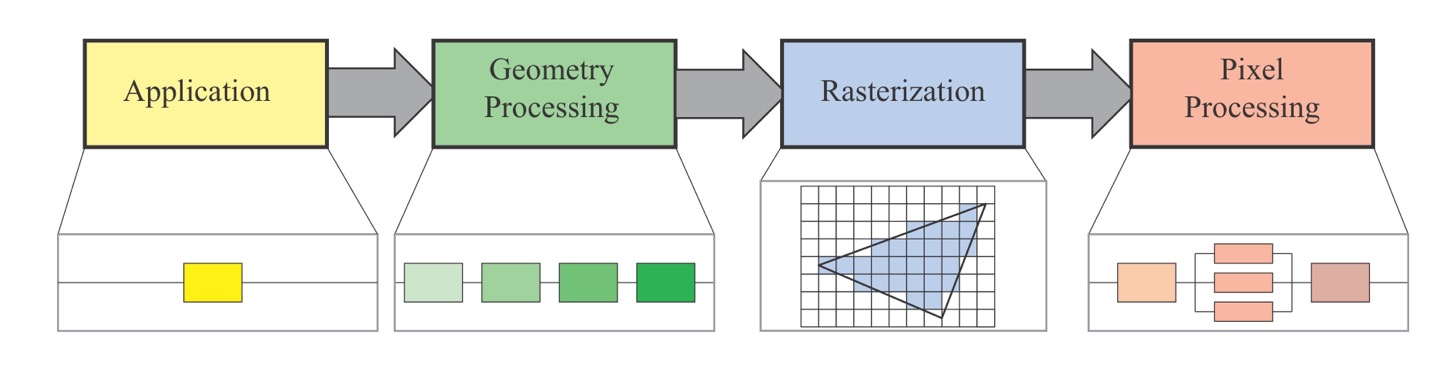
GPU는 개념적 geometry processing, rasterization, 그리고 pixel processing pipeline을 지원합니다. 파이프라인에서 고정된 함수들도 존재하는 반면, 프로그래밍 가능한 부분도 존재합니다. 논리적 파이프라인의 구체화인 물리적 모델이 하드웨어에 종속되어 있고, 다른 파이프라인에 대해서도 이해함으로서 더 좋은 프로그래밍을 할 수 있게 될 것입니다.
vertex shader와 geometry shader의 경우는 프로그래밍 가능한 작업입니다. tesselation과 geometry shader는 선택할 수 있는 부분이며, 모든 GPU가 지원하지는 않습니다. clipping, triangle setup, triangle traversal 단계는 고정된 함수 하드웨어에 의해 수행됩니다. pixel shader 단계는 프로그래밍 가능하며, merger stage는 프로그래밍은 불가능 하지만, 유연성이 높으며 다양한 작업을 설정할 수 있습니다.
3.3. The Programmable Shader Stage
현대 shader 프로그램들은 통일된 shader 디자인을 사용합니다. 이는 vertex, pixel, geometry 및 tesselation 관련 shader와 같은 것이 공통된 프로그래밍 모델을 공유합니다. 이들은 동일한 ISA(instruction set architecture)을 가지며, common-shader core를 포함하여, shader 프로세서가 다양하게 쓰일 수 있고 GPU가 이에 맞춰 사용되도록 만들었습니다. 즉, 통일된 shader core에서는 병목 현상이 일어나지 않도록 적절하게 작업을 분배합니다. 여기에 HLSL, GLSL 등이 사용되며, 기본적으로 32비트 floating point scalar 및 벡터를 사용하여 색, 위치 등 다양한 정보를 담습니다.
draw call은 그래픽 API가 프리미티브들을 그릴 때 사용하는 것으로, 그래픽 파이프라인과 shader을 작동시킵니다. 쉐이더는 두 가지 종류의 입력을 받는데 uniform은 일정한 데이터를 제공하고, varying은 픽셀마다 다른 데이터를 제공합니다.
기저의 가상 머신이 다른 두 타입의 입력과 출력을 처리하게 해줍니다. uniform을 위한 constant register의 수가 보통 varying을 위한 레지스터보다 더 많습니다. 이는 varying 입출력은 각각의 정점이나 픽셀에 대해 따로 저장되어 공급 값의 한계가 존재하기 떄문입니다. 하지만 uniform은 한번 저장되고 모든 픽셀과 정점에 대해서 다시 사용됩니다.
연산은 대부분 *, +의 기본 연산으로 수행되며, 내재된 sqrt, atan과 같은 함수도 존재하여 최적화되어 있습니다.
if와 case를 통한 흐름 제어도 존재하는데, 두가지 종류가 존재하여, 정적 흐름 제어는 uniform 입력에 의해 분기가 생기는 것으로 다양한 상황의 값을 하나의 쉐이더에서 수행할 수 있도록 하며, 스레드 분기가 생기지 않아 같은 코드 흐름을 지니게 됩니다. 동적 흐름 제어의 경우는 varying 입력에 의해 생기며 이는 Fragment마다 코드가 다르게 동작하여 더 강력하지만, 더 많은 자원을 소모하게 됩니다.
3.4. The Evolution of Programmable Shading and APIs
유구한 역사와 전통을 자랑합니다. 시간되면 읽어보겠습니다. 아마 안 읽을 듯…
3.5. The Vertex Shader
vertex shader는 기능적 파이프라인의 첫 번째 단계입니다. 삼각형은 정점의 집합으로 표현되며, 이는 각각 모델 표면의 특정한 점을 가리키며, 위치, 색과 같은 특성을 포함하고 있습니다. vertex shader는 삼각형을 다루는 첫번째 단계로, 정점만을 다룹니다. vertex shader는 삼각형의 각 정점의 데이터를 다루어 다양한 모델 좌표를 동일한 카메라 좌표로 옮겨지도록 합니다. vertex shader는 unified shader와 유사한데, vertex shader를 통과하는 정점은 독립적으로 작업이 수행되며 값은 변경되지만, 생성, 파괴되거나 다른 정점으로 치환되지 않습니다. vertex shader를 통과한 결과들은 바로 pixel fragment로 갈 수도 있지만, tesselation이나 geomtery shader를 거치거나, 데이터로서 저장될 수도 있습니다.
3.6. The Tessellation Stage
tesselation 단계를 쓰는 이점은, 본래의 모델보다 좀 더 세심하거나 단순하게 표현할 필요가 있을 때 삼각형을 조절할 수 있으며, CPU와 GPU 사이의 데이터 전송할 것이 많아 병목 현상이 생기는 경우, 추가적인 데이터를 GPU에서 생성이 가능하는 등 다양하게 존재합니다.
tesselation 단계는 3가지 구성요소로 이루어지는데, hull shader(tesselation control shader), tesselator, domain shader(tesselation control shader)로 구성됩니다.
hull shader의 입력 값은 특별한 조각 프리미티브로 부분 표면을 저으이하기 위한 여러개의 제어 포인트로 구성되어 있습니다. hull shader는 두개의 기능을 지니는데, 첫번째는 Tesselator에게 얼마나 많은 삼각형이 만들어져야 하며, 어떤 설정이어야 하는지를 얘기하며, 제어 포인트에 대해서 작업을 수행하는 것입니다. 또한, 제어 포

인트를 변경 및 생성, 삭제할 수 있습니다.
tesselator는 파이프라인에서 고정된 함수로, domain shader에서 작업을 수행할 새로운 정점을 만들어 냅니다. hull shader가 tesselator에게 어떤 정점을 Domain shader에게 추가해줄 지를 얘기해줍니다. 또한 tesselation factor도 보내주는데, 이는 내부 모서리와 외부 모서리가 존재하여, 내부에서 얼마나 삼각형이 만들어지며, 외부에 얼마나 edge가 나뉘어질 지를 결정합니다.
domain shader는 tesselator에서 받은 입력 정점과 이에 해당하는 출력 정점을 생성하는 것이 vertex shader와 같은 데이터 흐름 패턴을 지닙니다. 이를 통해 삼각형이 구성되고 파이프라인을 따라 흘러갑니다.
3.7. The Geometry Shader
geometry shader는 tesselation 단계에서는 할 수 없는 작업인 프리미티브를 다른 프리미티브로 바꾸는 작업을 수행합니다. 예를 들어 삼각형이 와이퍼 프레임 형태가 되도록 만들 수 있습니다. geometry shader의 입력 값은 하나의 물체와 이와 관련된 정점으로, 물체는 삼각형으로 이루어져, 여기서 확장된 프리미티브가 geometry shader에서 정의 가능해집니다. 해당 단계에서는 정점을 더 추가하여 새로운 정점 편집하거나, 새로운 프리미티브를 만들 수 있게 됩니다.
geometry shader는 입력값을 변경하거나, 복사본을 만들 수 있어, 큐브 맵의 모든 면을 한번에 다 보여주는 것도 가능합니다. geometry는 입력한 primitives 순서대로 나오는 것을 보장하는데, 이는 성능에 영향을 줄 수 있습니다.
3.7.1 Stream Output
GPU 파이프라인의 표준 사용은 vertex shader를 통과한 삼각형이 rasterize되어 pixel shader로 넘어가는 것입니다. 이 도중의 값들은 접근할 수 없었습니다. stream output이라는 개념은 vertex shader를 지난 정점에 대해서 stream으로 출력하면서 rasterization 단계로 넘기지 않아도 무관합니다. 이런 식으로 진행되는 데이터는 파이프라인에서 돌아와 반복적인 작업을 수행하도록 합니다. stream output은 오직 float만을 리턴하는데, 이는 비용이 꽤 듭니다. stream output은 정점이 아닌 primitive에 대해 작업을 수행하는데, 각각의 삼각형은 3개의 정점의 집합을 출력하게 되며, 원래 mesh에서 공유되던 정점은 값을 잃게 됩니다.
3.8. The Pixel Shader
vertex, tesselation 그리고 geometry shader의 작업이 끝나고, primitive는 clipping되어 rasterization을 수행하게 됩니다. 이번 장에서는 비교적 고정되어 있는 단계로, 수정은 가능하지만 프로그래밍은 불가합니다. 각 삼각형은 어떤 픽셀을 덮는지 순회하며 확인하게 되고, 이러한 픽셀을 fragment라고 합니다. 이때의 값들은 정점에서 보간된 값을 가지게 되며, 이들은 pixel shader로 전송 되어집니다.
pixel shader는 이렇게 받은 값들을 계산하고 fragment 색을 도출해냅니다. 이는 불투명한 색을 내거나, z-depth 버퍼를 조절할 수도 있으며, 이러한 값들을 통해 pixel에 저장된 값을 변경합니다. stencil buffer는 변경될 수 없지만, merge 단계에서 통과될 수 있습니다.
pixel shader는 또한 fragment 값을 받고 아무런 출력도 하지 않을 수 있는데, 이는 mesh의 부분만을 나타내게 만들 수도 있습니다.
MRT(multi render targets)의 등장으로 pixel shader는 단순히 merging 단계만을 수행하던 것이 다양한 작업을 수행할 수 있도록 변경되었는데, 색과 z-buffer에 pixel shader 프로그램의 결과값을 보내는 것 대신에, 값들의 집합이 다른 버퍼나 fragment에 생성되도록 합니다. 이를 render target이라고 하는데, 이러한 구조는 depth, data format을 똑같이 가져가면서, GPU에 따라 여러개를 지닐 수도 있습니다. 이는 다양하게 사용될 수 있는데, deferred shading 혹은 나온 결과 값에 다양한 변화를 주어 다양한 렌더링 알고리즘을 수행할 수 있습니다.
pixel shader의 한계는 주어진 fragment 위치에 대해서만 render target을 적을 수 있고 주변에는 영향을 끼치지 못한다는 점입니다. 하지만 이는 다른 기술을 사용하면 해결할 수 있으며 이는 12장에서 소개됩니다. 또한 이에는 예외 사항이 있는데, 미분 혹은 gradient를 적용할 때 주변의 정보에 접근할 수 있다는 것입니다. pixel shader는 x와 y축을 따라서 보간 값들이 주어지는데, 이들은 다양한 계산과 텍스쳐링에 사용됩니다. 이때 pixel shader에서 2 x 2형태의 fragment 집합인 quad를 요청하면, 이에 현재 픽셀의 값과의 차이를 받아 올 수 있는데, 이를 통해 gradient 계산을 수행할 수 있습니다.
3.9. The Merging Stage
merging 단계는 각 fragment의 깊이와 색을 framebuffer와 혼합하는 단계입니다. 전통적인 파이프라인에서는 이는 stencil-buffer와 z-buffer 연산으로 수행되었습니다. 깊이를 통해 그릴 지 여부를 확인하고, 투명하다면 blending을 수행합니다.
z-buffer에 의해서 fragment가 그려질 지 정해지기 때문에, depth-testing을 통해 먼저 계산 여부를 판단하며 이를 early-z라고 합니다.
Merging 단계는 직접 프로그래밍이 가능하지는 않지만, 설정 가능하여 많은 작업이 수행가능 합니다. Blending이 그 예시이며, 색에 대해 다양한 연산이 가능합니다.
3.10. The Compute Shader
GPU는 전통적인 그래픽 파이프라인만이 아니라 여러 계산을 위해서도 사용 가능합니다. 이러한 방법을 GPU computing이라고 하며, CUDA 및 OpenCL에서는 이를 거대한 병렬 프로세서로서 제어합니다.
이러한 compute shader의 장점은 GPU에서 생성된 데이터에 접근할 수 있다는 점입니다. CPU에서 보내는 것은 지연을 발생시키기에, 이는 결과물을 계속 GPU 메모리에 둠으로서 효율을 극대화 시킬 수 있습니다. 이는 Post-processing에 사용될 수 있습니다.
또한 파티클 시스템이나, culling, shadowing 등 연산을 많이 필요로 하는 작업에 사용 가능합니다.
'그래픽 공부 > Realtime Rendering' 카테고리의 다른 글
| Chapter 5. Shading Basics (0) | 2022.07.26 |
|---|---|
| 2. The Graphics Rendering Pipeline (0) | 2022.07.11 |
| 21. Virtual and Augmented Reality (0) | 2022.05.11 |
| 8. Light and Color (0) | 2022.05.11 |